The Scottish Health Survey 2008
The Scottish Health Survey 2008
CHAPTER 1: METHODOLOGY AND RESPONSE
Catherine Bromley, Joan Corbett, John D'Souza, Lisa Given and Martine Miller
1.1 INTRODUCTION
1.1.1 The Scottish Health Survey series
The Scottish Health Survey ( SHeS) series was established by the Scottish Office in 1995 to provide data about the health of the population living in private households in Scotland. The 1995 and 1998 surveys were carried out by the Joint Health Surveys Unit of the National Centre for Social Research and the Department of Epidemiology and Public Health, University College London Medical School ( UCL). In 2003, a third organisation, the MRC Social and Public Health Sciences Unit at the University of Glasgow ( MRCSPHSU) joined the consortium.
During 2005 and 2006 a comprehensive review of the survey was carried out by the then Scottish Executive. 1 One of the key recommendations to emerge from the review was that the survey should be carried out on a more frequent basis. This recommendation was adopted and the survey began running continuously in 2008. The next section includes a summary of the other key recommendations that were implemented. A consortium made up of the Scottish Centre for Social Research 2 (ScotCen), UCL and MRCSPHSU will be carrying out the 2008-2011 surveys.
Each survey in the series consists of main questions and measurements (for example, anthropometric and, if applicable, blood pressure measurements and analysis of blood and saliva samples), plus modules of questions on specific health conditions. As with the earlier surveys in the series, the principal focus of the 2008 survey was cardiovascular disease ( CVD) and related risk factors. CVD is one of the leading contributors to the global disease burden. Its main components are ischemic heart disease ( IHD) and stroke. IHD is the second most common cause of death in Scotland after cancer. 3 The SHeS series means that there are now trend data going back for over a decade, and providing the time series is an important function of the survey.
1.1.2 Key changes to the survey methodology in 2008
A number of changes to the survey methodology were proposed during the series review and were adopted for the 2008 survey. The key changes to the survey methodology in 2008 are:
Move to a continuous format - Prior to 2008, the survey had been carried out on three occasions 1995, 1998 and 2003. The review recommended that the survey be carried out more frequently than this and is now being carried out continuously between 2008 and 2011.
Reduced Stage 2 nurse visit - Unlike the three previous surveys, only a sub-sample of adults are eligible to take part in the nurse visit in the 2008-11 surveys. No nurse visits are carried out with children, or with adults in the Health Board boost sample. The nurse sample is designed to allow for analysis of nurse data at the national level after one year. More detailed analysis of sub-groups within the sample will be possible once two or more years of data have been aggregated (the format of the nurse visit and the measurements and samples taken will remain the same in the four years to permit this).
Core and modular questionnaire structure - The Stage 1 interviewer visit now has a core and modular structure with a core set of questions asked of the whole sample and two modules of questions which are asked of a proportion of the sample. Core questions will be included in the survey every year and these will be analysable by Health Board after four years. Module A is the 'rotating' biennial module. In 2008 it contained a range of questions on cardiovascular disease, asthma, eating habits for adults, and physical activity. It is anticipated that these questions will be asked again in 2010. A module with different topics is being included in 2009 and 2011. Module B contains questions on knowledge, attitudes and motivations to health and is a replacement for the Health Education Population Survey ( HEPS) which was previously run by NHS Health Scotland. See Section 1.3 for a more detailed description of the Stage 1 and 2 questionnaire content.
Unclustered sample design - The sampling was constructed so that each year's sample was clustered but the four-year sample 2008-2011 was unclustered. See Section 1.2 for a detailed description of the sample design.
Optional NHS Health Board boost - NHS Health Boards were given the option to boost their samples beyond the level which is funded centrally. In 2008, three Health Boards, Borders, Fife and Grampian chose to boost the number of adults interviewed in their area.
1.1.3 The 2008 survey
The 2008 Scottish Health Survey was designed to provide data at the national level about the population living in private households in Scotland. The age range for the survey in 2008 was those aged 0+.
An initial sample of 9,906 addresses was drawn from the Postcode Address File ( PAF). These addresses were comprised of three sample types: 6,945 formed the main sample, at which adults and children were eligible to be selected for interview; 2,301 addresses formed an additional child boost sample at which only households containing children aged 0-15 were eligible to participate; the remaining 660 addresses formed the Health Board boost sample at which only adults were eligible for interview. The 9,906 addresses were grouped into 492 interviewer assignments, with around 45 assignments being issued each month to interviewers between February and December 2008.
Borders, Fife and Grampian Health Boards opted to boost the number of adults (16+) interviewed in their area in 2008. An additional sample of 220 addresses was drawn in each of these areas and were grouped into 11 interviewer assignments of 20 addresses each.
Sample type |
Number of addresses |
|---|---|
Main |
6,945 |
Child Boost |
2,301 |
Health Board Boost |
660 |
Total |
9,906 |
Data collection involved a Stage 1 interview, and if applicable, adults also had a follow-up visit from a specially trained nurse. Of the 6,945 main addresses issued, 1,859 were flagged as the 'nurse sample'. At these addresses all adults (16+) interviewed at Stage 1 were eligible to take part in the Stage 2 follow-up nurse visit. There were no nurse visits at the remaining addresses or for the child boost or health board boost samples. Due to a lower than anticipated response at the Stage 1 interview the number of addresses flagged as eligible for a nurse visit was increased in the last quarter of the year to ensure that the nurse sample contained sufficient cases.
1.1.4 The 2008 reports
This volume, which covers the methodology of the 2008 Scottish Health Survey, is one of two volumes based on the survey, published as a set as 'The Scottish Health Survey 2008':
1. Main Report
2. Technical Report
The report is available in both hard copy and on the web ( http://www.scotland.gov.uk/Topics/Statistics/Browse/Health/scottish-health survey/Publications).
1.1.5 Comparisons with previous Scottish Health Surveys
Topic chapters in the main 2008 report make comparisons with the 1995, 1998 and 2003 Scottish Health Surveys where possible. The report always states in the text or table which years' data form the basis for any comparisons.
1.1.6 Health Board level analysis
The first two SHeS reports included analysis by seven health regions based on amalgamations of the NHS Health Boards; this was discontinued in the 2003 report 4. The sample for the 2008-11 surveys was designed to be representative at the Health Board level for all boards after four years of data collection have taken place. For this reason the 2008 report does not include any analysis by NHS Health Board or any other sub-national geography. Health Board level analysis will be published after completion of the 2011 survey.
1.1.7 Access to data
As with previous surveys in the series, a copy of the 2008 Scottish Health Survey data will be deposited at the Data Archive at the University of Essex. Copies of anonymised data files can be made available for specific research projects through the Archive ( www.data-archive.ac.uk).
1.2 SAMPLE DESIGN
1.2.1 Overview of the main sample
The 2008 Scottish Health Survey used a two-stage stratified probability sampling design with datazones selected at the first stage and addresses (delivery points) at the second. This differed from previous years of SHeS where postcode sectors rather than datazones were the primary sampling units ( PSUs).
Three samples were selected for the survey:
1. a general population (main) sample in which all adults (16+) and up to two children (aged 0-15) were eligible to be selected in each household;
2. a child boost sample in which up to two children (aged 0-15) were eligible to be selected in each household; and,
3. a Health Board boost sample in which all adults (16+) were eligible to be selected in each household (in Borders, Grampian and Fife).
The sample of addresses was selected from the small user Postcode Address File ( PAF). This is a list of nearly all the residential addresses in Scotland and is maintained by The Royal Mail. The population surveyed was therefore people living in private households in Scotland. People living in institutions, who are likely to be older and, on average, in poorer health than those in private households, were not covered. The very small proportion of households living at addresses not on the PAF was not covered.
All areas of Scotland where fieldwork could feasibly be carried out were covered, but some inhabited islands with very small populations were excluded The inhabited islands that were included were mainland Orkney, mainland Shetland, Lewis, Harris, Skye, Bute, Islay, Mull and Arran.
1.2.2 Selecting the core sample
Prior to 2008 only NHS Health Boards were used as strata for sampling. A change in methodology was used for the Scottish Health Survey 2008 to include area deprivation. Twenty-five strata were created - each of the three island health boards (Orkney, Shetlands, and the Western Isles) was a stratum, and 22 other strata were constructed by dividing the 11 mainland Health Boards into separate strata containing "deprived" and "non-deprived" data zones. A deprived area was defined as being within the most deprived 15% of areas according to the 2006 Scottish Index of Multiple Deprivation. Having these separate strata allowed us to over-sample deprived areas.
The sampling was constructed so that each year's sample is clustered but the four-year sample 2008-2011 is unclustered. This meant that the design of the four-year sample would need to be considered at the start of the four-year period. However, it was not possible to select a sample of addresses at the start of the period. Had this been done then it is likely that the sample in the later years would have had a high level of ex-residential addresses (i.e. demolitions and conversion to other uses), and any new residential properties built over the four-year period would not have been included. The solution was to sample datazones for the four-year period and sample addresses each year. We used the following sampling procedure:
(i) Firstly, the numbers of addresses needed to be issued in each stratum over a four-year period were calculated.
(ii) Next, the number of addresses needed to be sampled in each datazone over the four-year period to achieve the numbers in (i) was calculated.
(iii) To ensure that each year's sample was geographically clustered the datazones were put into batches, with each batch containing datazones geographically close to each other. A quarter of the batches (approximately) were randomly assigned to each of the four survey years.
(iv) The Year 1 (2008) addresses were selected from the batches assigned to the first year and once the addresses were chosen they were clustered into interviewer assignments. Each assignment consisted of approximately 20 addresses.
(v) Finally, each assignment was allocated at random to a quarter, and then to a survey month. (Year 1 consisted of 11 survey months - February to December - but years 2-4 will include all 12 months).
The random assignments (of batches of datazones to years, and of interviewer assignments to quarters and months) were not implemented using simple random samples, but by using systematic random list samples chosen after ordering the list by the SIMD 2006 variable. This ensured an even spread of addresses (by deprivation variable) among the four years, and within each year by month.
The next sections describe the process of (i) - (v) in more detail.
(i) and (ii) Sample sizes
The survey was designed to allow analysis at Health Board level and SIMD 15 level every four years. In order to do this the sampling fraction (the proportion of addresses sampled) varied by Health Board and SIMD15 area. Smaller Health Boards and the SIMD15 areas were over-sampled. The sampling fraction also varied according to expected response rate (areas with an expected low response rate were over-sampled).
The number of addresses initially planned to be issued over a four-year period is given below:
Figure 1A: Number of main-sample addresses selected in each Health Board (initial 4-year allocation)
Health Board |
Non-deprived datazone |
Deprived datazone |
Total |
|---|---|---|---|
Ayrshire & Arran |
1285 |
298 |
1583 |
Borders |
829 |
24 |
853 |
Dumfries & Galloway |
809 |
67 |
876 |
Fife |
1547 |
246 |
1793 |
Forth Valley |
1057 |
177 |
1234 |
Grampian |
2296 |
149 |
2445 |
Greater Glasgow & Clyde |
4020 |
2652 |
6672 |
Highland |
1295 |
115 |
1410 |
Lanarkshire |
1981 |
548 |
2529 |
Lothian |
3658 |
476 |
4134 |
Orkney |
754 |
0 |
754 |
Shetland |
762 |
0 |
762 |
Tayside |
1623 |
368 |
1991 |
Western Isles |
769 |
0 |
769 |
Total |
22685 |
5120 |
27805 |
The number of addresses we needed to sample from each datazone was proportional to the size of the datazone. (Typically 3-5 addresses would be chosen in each datazone). Choosing the number proportional to the size ensured that within each stratum each address had an equal probability of being chosen. The selection probabilities varied by stratum.
(iii) Assigning datazones to batches
The datazones were then grouped into 1865 initial batches, each consisting of datazones geographically close to each other. Each batch was chosen so that it was small enough to form an assignment. The typical batch contained approximately 13-18 addresses (typically consisting of 3-5 datazones).
The mean SIMD 2006 score of the datazones in each batch was used as a measure of deprivation of the batch and within each Health Board the batches were ordered according to their deprivation measures and put into groups of four batches. One batch from each group was then randomly allocated to each of four years. This ensured that each year's sample would be representative of Scotland as a whole.
The first year's sample consisted of 6,945 addresses, allocated as shown in Figure 1B.
Figure 1B: Number of main-sample addresses selected in each Health Board (Year 1)
Health Board |
Non-deprived datazone |
Deprived datazone |
Total |
|---|---|---|---|
Ayrshire & Arran |
313 |
76 |
389 |
Borders |
209 |
0 |
209 |
Dumfries & Galloway |
205 |
14 |
219 |
Fife |
394 |
57 |
451 |
Forth Valley |
266 |
43 |
309 |
Grampian |
581 |
31 |
612 |
Greater Glasgow & Clyde |
984 |
679 |
1663 |
Highland |
321 |
36 |
357 |
Lanarkshire |
494 |
143 |
637 |
Lothian |
930 |
114 |
1044 |
Orkney |
191 |
0 |
191 |
Shetland |
182 |
0 |
182 |
Tayside |
395 |
100 |
495 |
Western Isles |
187 |
0 |
187 |
Total |
5652 |
1293 |
6945 |
(iv) Selection of addresses and assignments
Once the first year's batches of datazones were chosen, a sample of addresses was selected from these datazones using the small user Postcode Address File ( PAF). We then needed to combine addresses into interviewer assignments (points). It would have been possible to make each interviewer assignment a batch. However, this would have created interviewer assignments on the basis of the chosen datazones and it is more efficient to create them on the basis of the chosen addresses, so once the addresses had been obtained the interviewer assignments were created from the sampled addresses.
(v) Allocating assignments to months
The Year 1 assignments were then ordered according to their SIMD 2006 scores and randomly allocated to quarters of the year so that the sample for each quarter was representative of the population. The sample within each quarter was then randomly allocated to fieldwork months.
Sampling households
One issue when sampling addresses in Scotland is the presence of tenement blocks and other multi-residence buildings, some of which have only one address entry in the PAF but contain a number of different flats (dwelling units). Such addresses are identified in the PAF by the Multiple Occupancy Indicator ( MOI) which is an estimate of the number of dwelling units at an address. To ensure that households in tenement blocks that do not have an individual entry in the PAF were given an equal chance of selection to other households the likelihood of selecting each address was increased in proportion to the MOI.
Where interviewers found more than one dwelling unit at an address they chose one dwelling unit at random 5. If the chosen dwelling unit contained four or more households they chose three of them at random for inclusion in the survey; if the dwelling unit contained three or fewer households all households would be chosen.
In most cases this meant that every household in a stratum had the same probability of selection - the exceptions being households at addresses with an incorrect MOI or at a dwelling unit containing four or more households. In these cases equal probability could be restored by applying a corrective weight at the analysis stage.
Sampling individuals within households
For the main sample all adults aged 16 years and over at each household were selected for the interview (up to a maximum of ten adults). However, in order to limit the burden on households with three or more children (aged 0-15), two of the children were randomly selected for inclusion in the survey. No interviews were attempted with the other children in the household.
1.2.3 Selecting the child boost sample
In addition to the main sample, a child boost sample of 2,301 addresses was issued. Whereas the main sample had been chosen to allow analysis of Health Boards in each four year period, the child sample is designed only to allow national estimates. Because of this, addresses were not issued in the smaller Health Boards that had been over-sampled in the main sample, but were issued in nine of the 14 Health Boards.
The following numbers of addresses were chosen:
Figure 1C: Number of addresses selected for the child boost in each Health Board (Year 1)
Health Board |
Non-deprived datazone |
Deprived datazone |
Total |
|---|---|---|---|
Ayrshire & Arran |
150 |
30 |
180 |
Fife |
158 |
24 |
182 |
Forth Valley |
146 |
18 |
163 |
Grampian |
238 |
10 |
249 |
Greater Glasgow & Clyde |
382 |
165 |
547 |
Highland |
137 |
12 |
149 |
Lanarkshire |
279 |
54 |
333 |
Lothian |
284 |
43 |
327 |
Tayside |
142 |
29 |
171 |
Total |
1916 |
385 |
2301 |
1.2.4 Selecting the Health Board boost sample
In addition to the main sample, three of the Health Boards (Borders, Fife and Grampian) had a Health Board boost. The sampling scheme for the Health Board boosts differed slightly from that of the main sample. In order to minimize fieldwork costs a two-stage system with postcode sectors selected in the first stage and addresses in the second was used. Eleven postcode sectors were chosen in each Health Board, these formed the primary sampling units, and 20 addresses selected from each postcode sector. Thus, the Health Board boost consisted of 220 addresses in each of the Health Boards. In both Borders and Grampian the postcode sectors chosen for the Health Board boost were chosen by taking a simple random sample, but the sampling scheme in Fife differed slightly. Fife addresses were stratified by Community Health Partnership ( CHP) before selection, and selection probabilities were chosen to enable analysis of data at the CHP level data at the end of the four-year period.
The method of selecting households and individuals within households followed that of the main sample.
1.2.5 Selecting the nurse sample
Some addresses from the main sample were selected as nurse addresses. Initially 1859 addresses were assigned to be nurse addresses. These were spread evenly throughout the year with approximately equal numbers of nurse addresses issued per month. However, because of a low initial response rate an additional 371 addresses were later assigned to have nurse visits. These additional addresses were not assigned to the island Health Boards, and were only assigned to the last three months of the year. As health measures are sensitive to seasonal effects this needed to be corrected for in the weighting.
Figure 1D: Number of addresses selected for nurse visits in each Health Board (Year 1)
Area |
Non-deprived datazone |
Deprived datazone |
Total |
|---|---|---|---|
Ayrshire & Arran |
113 |
23 |
136 |
Borders |
49 |
0 |
49 |
Dumfries & Galloway |
55 |
4 |
59 |
Fife |
138 |
17 |
155 |
Forth Valley |
92 |
15 |
107 |
Grampian |
208 |
9 |
217 |
Greater Glasgow & Clyde |
377 |
213 |
590 |
Highland |
117 |
8 |
125 |
Lanarkshire |
177 |
46 |
223 |
Lothian |
334 |
35 |
369 |
Orkney |
6 |
0 |
6 |
Shetland |
7 |
0 |
7 |
Tayside |
149 |
30 |
179 |
Western Isles |
8 |
0 |
8 |
Total |
1830 |
400 |
2230 |
The addresses chosen to be assigned to have a nurse visit were selected using the following randomization schemes.
- In the island Health Boards (Orkney, Shetland and the Western Isles) clustered samples were used. Two points (interviewer assignments) were chosen from each Health Board and addresses were selected at random from these points to have a nurse visit. The six points chosen were chosen at random while ensuring that each Health Board's points had been assigned to consecutive months (this helped reduce costs), and the six points covered all seasons of the year.
- In mainland Scotland an unclustered sample of addresses was taken.
Every adult in these addresses that participated in the stage 1 interview was eligible for a nurse visit.
As the amount of clustering in the nurse sample is small (only 21 of the 2,230 addresses were clustered) the sample can be treated as an unclustered sample for analysis purpose.
1.2.6 Selecting the knowledge, attitudes and motivations to health ( KAM) sample
The 6,945 addresses selected for the main sample were classified as being either version A, or version B ( KAM) addresses - 2,708 were version A addresses, 4,237 were version B. Random allocation was used to choose the version assigned. Core questions were asked of each respondent, but each respondent in the version A addresses was also given Module A, while in version B addresses a single adult, chosen at random, was given the KAM module.
1.3 TOPIC COVERAGE
1.3.1 Introduction
As part of the SHeS review a consultation on which questions should be included in the survey was carried out in 2007. 6 Many of the topics included in previous years have been included in the 2008 survey and, as with previous years, the survey had a focus on cardio-vascular disease ( CVD) and its risk factors. However, as a result of the consultation exercise and extensive piloting of the questionnaire there have been some changes to both topics and questions within topics since the 2003 survey.
1.3.2 Documentation
Copies of all the survey data collection documents are included in Appendix A. Protocols for measurements and for the collection of saliva, urine and blood samples are included in Appendix B. Full copies of the Stage 1 and Stage 2 questionnaire documentation are included in Appendix A. A summary of the content of both stages is summarised below.
1.3.3 Stage 1 interview
Information was collected at household level and at individual level. The table that follows summarises the content of the household and individual level interviews for all participants, by age group.
Figure 1E: Content of the 2008 Stage 1 interview
Stage 1 interview outline |
|
|---|---|
Version A |
Version B |
Household questionnaire including household composition |
|
General health including caring (0+) |
|
Respiratory & CVD symptoms (16+) |
- |
General CVD (16+) and use of services (0+) |
|
Asthma (0+) |
- |
Physical activity adults (16+) and children (2-15) |
|
TV viewing & outdoor physical activity adults (16+) and children (2-15) |
- |
Eating habits children (2-15) |
|
Eating habits adults (16+) |
- |
Fruit and veg consumption (2+) |
|
Smoking and Drinking (16+) [16-19 in a self completion] |
|
Dental health (16+) |
|
Economic activity and education (16+) |
|
Physical activity at work (16+) |
- |
Ethnicity, religion and family health background (16+) |
|
Self-completions (13+ & parents of 4-12 yr olds) |
|
Height (2+) and Weight (0+) |
|
Data linkage and follow-up research consents (0+) |
|
- |
Attitudes to Health (16+) |
The questions on CVD were based on those used in 1995, 1998 and 2003. Previously used modules on asthma, physical activity, alcohol consumption, smoking, eating habits, fruit and vegetable consumption, economic activity and education, ethnicity, religion and family background were also included. A new module was introduced on adult dental health.
Children aged 13-15 were interviewed directly, and parents/guardians of children aged 0-12 were asked to answer on behalf of their children.
Participants aged 13 and over were asked to fill in a self-completion booklet during the interview. There were four booklets for different age groups as specified below. The booklet for young adults aged 16-17 asked about smoking and drinking behaviour and interviewers also had the option of using the booklet for those aged 18-19 if they felt that it would be difficult for anyone in this age group to give honest answers in the face to face interview with other household members present.
Booklet for adultsCAGE questions on drinking experiences, GHQ12, Warwick Edinburgh Mental Well-being scale ( WEMWBS), use of contraception and sexual orientation
Booklet for young adults Smoking, drinking, CAGE questions on drinking experiences, GHQ12, WEMWBS, use of contraception and sexual orientation
Booklet for 13-15 year oldsGHQ12
Booklet for parents of 4-12 year olds Strengths and Difficulties Questionnaire ( SDQ) designed to detect behavioural, emotional and relationship difficulties in children.
Interviewers measured the weight of all participants, and the height of all participants aged 2 and over.
1.3.4 Stage 2 interview
Nurse visits were offered to adults (aged 16+) at a sub-sample of households in the main sample.
At the nurse visit, participants were asked about their use of prescribed medication, vitamin supplements, and nicotine replacement therapy, and about recent experiences of food poisoning. A new module of questions about depression, anxiety and self-harm (taken from the Psychiatric Morbidity Survey) was also included in the nurse visit. The nurse also took the following measurements: blood pressure; waist and hip circumference; and arm-length (demi-span) (age 65+). Lung function was measured via a spirometer. With written agreement, a small sample of blood was taken by venepuncture and was analysed for Total and HDL-cholesterol, C-reactive protein, Fibrinogen and Glycated haemoglobin. Nurses also sought agreement for the storage of a small sample of blood for possible future analysis. Written agreement was also sought to take samples of saliva (for the analysis of cotinine, a derivative of nicotine) and spot urine samples (for the analysis of dietary sodium).
Figure 1F: Content of the 2008 Stage 2 nurse interview
Outline of Stage 2 nurse visit |
|---|
Prescribed medicines (age 16+) |
Vitamin supplements (age 16+) |
Nicotine replacement therapy (age 16+) |
Blood pressure (age 16+) |
Depression, anxiety and self-harm (age 16+) |
Food poisoning (age 16+) |
Waist and hip measurements (age 16+) |
Demi-span (arm length) (age 65+) |
Lung function (age 16+) |
Blood sample (age 16+) |
Saliva sample (age 16+) |
Urine sample (age 16+) |
1.4 FIELDWORK PROCEDURES
1.4.1 Advance letters
Each sampled address was sent an advance letter that introduced the survey and stated that an interviewer would be calling to seek permission to interview. There were two versions of the advance letter; one for the main and Health Board boost addresses in the sample and a separate version for the child boost addresses. A copy of the survey leaflet was included with every advance letter. The survey leaflet introduced the survey, descried its purpose in more detail and included some summary findings from previous surveys.
1.4.2 Making contact
At initial contact, the interviewer established the number of dwelling units ( DUs) and/or households at an address and made any selection necessary (see Section 1.2).
The interviewer then made contact with each household. In the main sample they attempted to interview all adults (up to a maximum of ten) and up to two children aged 0-15 (see Section 1.2). At child boost sample addresses, interviewers first screened for children aged 0-15 and within such households up to two children were selected for interview. The interviewer sought parents' and children's consent to interview selected children. Interviewers attempted to interview a maximum of ten adults at selected households in the Health Board boost sample.
1.4.3 Collecting data
Both interviewers and nurses used computer assisted interviewing.
At each co-operating eligible household in all sample types, the interviewer first completed a Household Questionnaire, information being obtained from the household reference person 7 or their partner wherever possible. This questionnaire obtained information about all members of the household, regardless of age. The program created individual questionnaires for adults in the main and Health Board boost samples, and for selected children in the main and child boost samples.
An individual interview was carried out with all selected adults and children. In order to reduce the amount of time spent in a household, interviews could be carried out concurrently, the program allowing for up to four participants to be interviewed in a session.
Height and weight measurements were obtained towards the end of the interview.
In addition to an advance letter and general survey leaflet, participants were also given a more detailed leaflet describing the contents and purpose of the Stage 1 interview. Adults in those main households eligible for a nurse visit were given a longer version of this leaflet which also included an explanation of the purpose of the Stage 2 nurse visit. There was a separate version of this leaflet for children in main and child boost households. Parents at child boost addresses were also given a leaflet containing background information on the survey. Stage 1 leaflets are included in Appendix A.
1.4.4 Introducing the Stage 2 nurse visit
Unlike the 1995, 1998 and 2003 surveys, only a sub-sample of adults in the main sample were eligible to take part in the Stage 2 nurse visit. At the end of the Stage 1 interview, adult participants at the main 'nurse sample' addresses were asked for their agreement to take part in the second stage of the survey. Wherever possible an appointment was made for the nurse to visit within a few days of the interview. At this visit the nurse carried out the measurements described in Section 1.3.4 and obtained the saliva, blood and urine samples from those adults eligible and willing to provide these samples.
Before blood, saliva and urine samples were taken, written consent was obtained from the participant. Nurses also asked participants for consent to store part of the blood sample for additional analyses at some future date. If the participant agreed, written consent was obtained.
1.4.5 Interviewing and measuring children
Children aged 13-15 were interviewed directly by interviewers, permission having first been obtained from the child's parent or guardian. Interviewers were instructed to ensure that the child's parent or guardian was present in the home throughout the interview. Information about younger children was collected directly from a parent/guardian. Whenever possible, younger children were present while their parent/guardian answered questions about their health. This was partly because the interviewer had to measure their height and weight and it also ensured that the child could contribute information where appropriate.
1.4.6 Feedback to participants
If participants wished, interviewers recorded height and weight measurements on their Stage 1 information leaflet.
At the Stage 2 nurse visit each participant was given a Measurement Record Card in which the nurse entered the participant's waist and hip measurement, demi-span measurement (if applicable), blood pressure measurements and lung function results.
If they wished, participants were also sent the results of their blood sample analyses. They were also given the option of having their blood pressure, lung function readings and blood sample analyses also being sent to their GP. Written consent for results to be passed on to GPs was required for each of the measurements.
Nurses were issued with a set of guidelines to follow when commenting on participants' blood pressure readings (see Appendix B for details). If an adult's blood pressure reading was severely raised, nurses were instructed to contact the Survey Doctor at the earliest opportunity. Where permission had been given for results to be sent to a participant's GP, the Survey Doctor contacted the GP if any blood pressure, lung function or blood sample results were abnormal. In the absence of permission to contact GPs, the Survey Doctor contacted participants directly if they had abnormal results.
1.5 FIELDWORK QUALITY CONTROL AND ETHICAL CLEARANCE
1.5.1 Training interviewers and nurses
Interviewers were fully briefed on the administration of the survey, including screening for households with children in the child boost sample. They were given training in measuring height and weight, including a practice session.
All nurses were professionally qualified and proficient in taking blood before joining the Health Survey team. They attended a one and a half day training session at which they received equipment training and were briefed on the specific requirements of the survey with respect to taking blood pressure, anthropometric and lung function measurements, and taking blood, saliva and urine samples.
Full sets of written instructions, covering both survey procedures and measurement protocols, were provided for both interviewers and nurses ( Appendix B contains a copy of the measurement protocols).
All nurses and interviewers who had not previously worked on SHeS were accompanied by a nurse or interviewer supervisor during the early stages of their work to ensure that interviews and protocols were being correctly administered.
1.5.2 Checking interviewer and measurement quality
A large number of quality control measures were built into the survey at both data collection and subsequent stages to check on the quality of interviewer and nurse performance.
Recalls to check on the work of both interviewers and nurses were carried out at 10% of productive households.
The computer program used by interviewers had in-built soft checks (which can be suppressed) and hard checks (which cannot be suppressed) which included messages querying uncommon or unlikely answers as well as answers outside an acceptable range. For example, if someone aged 16 or over had a height entered in excess of 1.93 metres, a message asked the interviewer to confirm that this was a correct entry (a soft check), and if someone said they had carried out an activity on more than 28 days in the last four weeks the interviewer would not be able to enter this (a hard check). For children, the checks were age specific. Some infants were weighed by having an adult hold them; the weight of the adult on their own was entered into the computer followed by the combined weight of the infant and adult. A hard check was used to ensure that the weight entered for the adult alone did not exceed the weight of the infant and adult combined.
At the end of each survey month, the measurements made by each interviewer and nurse were inspected. Any problems (such as higher than average proportions of measurements not obtained, insufficient samples and so on) were discussed with the relevant nurse or interviewer by their supervisor.
1.5.3 Ethical clearance
Ethical approval for the 2008 survey was obtained from the Multi-Centre Research Ethics Committee for Wales ( REC reference number: 07/ MRE09/55).
1.6 SURVEY RESPONSE
1.6.1 Introduction to response analysis
This section looks at the response for sampled households (section 1.6.2), and then at the response of eligible individuals within those households, firstly for adults (section 1.6.3) and then for children (section 1.6.4). Individual response for adults and children is examined in two ways: overall response for all eligible individuals in the 'set' sample, and response for individuals within co-operating households.
Participants were asked to co-operate in a sequence of operations, beginning with a face-to-face interview, height and weight measurements, and if applicable, progressing to a nurse visit and ending with requests for blood, saliva and urine samples. Individual non-response accumulated through the survey stages.
Not every measurement obtained by an interviewer or a nurse was subsequently considered valid for analysis purposes. Full details of the numbers of measurements used for analysis, the number of exclusions and the reasons for them are given at the start of each relevant chapter.
1.6.2 Household response
Tables 1.1 and 1.2 show household response by Health Board, for the main and Health Board boost samples combined (Sample A) and for the child boost sample (Sample B). The interviews conducted as part of the three Health Board boost samples have been integrated into the main 2008 datafile as they were not intended to form stand alone samples in their own right. For this reason separate analysis of their response rates is not being conducted. The row labelled 'Total eligible households' shows the number of private residential households found at the selected addresses (after selection of a single dwelling unit and, up to three households when necessary).
Households described as 'co-operating' are those where at least one eligible person was interviewed at Stage 1, the interviewer stage. Households described as 'all interviewed' are those where all eligible persons were interviewed, and 'fully co-operating' are those where all eligible persons were interviewed, had height and weight measured and, if applicable, agreed to a nurse visit. Households where a participant was ineligible for a height or weight measurement because of a functional impairment or pregnancy are not counted as fully co-operating for this response analysis.
61% of eligible households (4,139) in Sample A took part in the 2008 Scottish Health Survey. At 49% of households in this sample, all eligible adults and children were interviewed. In sample B, the child boost sample, 64% of eligible households (345) co-operated with the survey, and in all but four of these households, all eligible children were interviewed. Table 1.1, Table 1.2
1.6.3 Individual response for adults
Overall response
There were 6,465 individual interviews with adults in the 2008 SHeS. A sub-sample of adults in the main sample were eligible to take part in the Stage 2 nurse visit. 1,123 adults saw a nurse and 903 gave a blood sample.
To calculate the response rate for individuals, rather than households, the total number of productive individual interviews, should be expressed as a proportion of the total number of adults in the sampled households. However, as not all sampled households participated in the survey the total number of adults in the sampled households is not known, and must be estimated. There are three groups of households to consider:
- Co-operating households (7,357 adults in 4,139 households, average 1.78 per household),
- Non co-operating households where information on the number of adults is known (2,529 adults in 1,460 households, average 1.73) and
- Non co-operating households about which nothing is known (1,202 households).
The most reasonable assumption is to attribute to the last group the same average number of adults (1.77) as for all households where the number is known (the sum of the first two groups). This assumption gives an estimated total of 12,008 eligible adults, known as the 'set' sample.
Evidence suggests that unproductive households tend to be smaller on average than productive households, so this estimate of the total number of eligible adults is likely to be too large, and response rates based on it will therefore be underestimates.
A further assumption is needed to provide separate 'set' samples for men and women. In non co-operating households where the number of adults was known, the numbers of men and women were not usually obtained. However, it can be assumed that the proportion of men and women in the estimated total sample is the same as for the adults in the 4,139 co-operating households. The proportions are 46.9% men and 53.1% women. Applying these proportions to the estimated total of adults gives 'set' samples of 5,638 men and 6,371 women.
Using the estimated total number of adults in sampled households, the adult 'set' sample, as a denominator, minimum response rates for the various stages were as follows:
Men |
Women |
All adults |
|
|---|---|---|---|
% |
% |
% |
|
Interviewed |
50 |
57 |
54 |
Height measured |
45 |
50 |
47 |
Weight measured |
44 |
48 |
46 |
Saw a nurse |
30 |
33 |
32 |
Waist and hip measured |
30 |
32 |
31 |
Blood pressure measured |
29 |
32 |
31 |
Agreed to give a blood sample |
26 |
28 |
26 |
Blood sample obtained |
25 |
26 |
25 |
Response to the interview was 57% among women and 50% among men. Table 1.3
Adult response in co-operating households
As adults' ages and other personal characteristics are not known in non co-operating households, indications of differences in response by these characteristics are confined to co-operating households. Tables 1.4 and 1.5 show the proportion of men and women in co-operating households who participated in the key survey stages, by age. These are summarised below:
Men |
Women |
All adults |
|
|---|---|---|---|
% |
% |
% |
|
Interviewed |
82 |
93 |
88 |
Height measured |
73 |
81 |
77 |
Weight measured |
72 |
78 |
75 |
Saw a nurse |
50 |
55 |
52 |
Waist-hip measured |
49 |
53 |
51 |
Blood pressure measured |
48 |
53 |
51 |
Blood sample obtained |
41 |
43 |
42 |
Saliva sample given |
47 |
50 |
49 |
Lung function measured |
47 |
51 |
49 |
Urine sample given |
47 |
50 |
49 |
In co-operating households, response was lowest among those aged 16-24 for both sexes though young men stand out as having particularly low cooperation rates, (59% for men and 74% for women aged 16-24). Response increased with age among men, to around 80% up to the 45-54 age group, and increased further to its highest rate among those aged 75 and over (97%). The pattern among women was a little more even across the age groups with a consistently high response rate of over 90% achieved among women aged 25 and over (ranging between 93% and 98%).
It should be noted that the lower levels of response to the height and weight measurements, and agreement to nurse visits, among men is largely a result of the fact that fewer men than women took part in the survey overall. Based on those participating, women's refusal rates for participating in the height and weight measurements were actually slightly higher than men's, while the same proportion of men and women who were interviewed refused a nurse visit or could not be contacted by the nurse (14%). Tables 1.4 and 1.5
1.6.4 Individual response for children (0-15)
Overall response among children
Interviews were carried out with 1,750 children aged 0-15. This includes 1,239 children interviewed in the main sample, and 511 interviewed in the child boost sample.
To calculate the response rate for children, the number of eligible children in sampled households (the 'set sample') is needed as the denominator. This was estimated by assuming that the households where the numbers of children were not known had the same average number of boys and girls as those where it was known (and that the proportion of boys and girls was the same). This results in a 'set' sample of 3,206 children in total, comprising 2,403 in the main sample and 802 in the child boost. This is likely to be an over-estimate, since non-contacted households have fewer children, on average, than those contacted. Response rates computed for children, like those for adults, are therefore conservative. Most non-responding children were in households where no-one (child or adult) co-operated with the survey. The total number of children in the sampled households would be slightly greater than the set sample as some households would have had more than two children.
In the main sample, response to the interview was 52% among boys and 51% among girls, while in the boost response was 64% and 63% respectively. Combining the two samples, this gives an overall response to the interview of 55% for boys and 54% girls. Height measurements were limited to those aged 2 and over. On the assumption that the age distribution of children in the 'set sample' is the same as that of children living in interviewed households, responses to these measurements were: Table 1.6
Boys |
Girls |
All children |
|
|---|---|---|---|
% |
% |
% |
|
Interviewed |
55 |
54 |
55 |
Height measured (aged 2 and over) |
42 |
41 |
41 |
Weight measured |
46 |
44 |
45 |
Child response in co-operating households
Child response rates, like adult response rates, have also been calculated on a co-operating household base. Among selected children aged 0-15 in co-operating households, the proportion who were interviewed was high at 94% of eligible boys and 95% of eligible girls. The proportion interviewed was slightly lower among children aged 11-15 (88% of boys and 92% of girls) than among those aged under 11. This may in part be accounted for by the fact that parents acted as proxy participants for all children aged 12 and under whereas from 13 onwards children were interviewed directly in person.
Tables 1.7 shows the proportion of boys and girls, by age, in co-operating households who participated in the key survey stages. These are summarised below: Table 1.7
Boys |
Girls |
All children |
|
|---|---|---|---|
% |
% |
% |
|
Interviewed |
94 |
95 |
95 |
Height measured (aged 2 and over) |
81 |
84 |
82 |
Weight measured |
79 |
78 |
78 |
1.6.5 Regional variations in survey response
As in previous years, response varied by Health Board. Household response was highest in the three island Boards (Shetland, Western Isles and Orkney). On the mainland it was highest in Dumfries and Galloway and Fife. Response was lowest in Lothian and Greater Glasgow and Clyde. Table 1.1, Table 1.2
1.6.6 Age and sex profile of the sample
Table 1.8 compares the age and sex profile of responding adults at the two survey stages (interview and nurse visit) with the mid-2008 household population estimates for Scotland. 8
According to the 2008 household population estimates, men form 48% of all adults (aged 16 and over) in Scotland and women form 52%. While in the SHeS 2008 men form 44% of all interviewed adults and women form 56%. In SHeS 2008 men aged under 45 are slightly under-represented at both the interview and nurse visit relative to their proportions in the household population estimates. Men aged 45 and over are slightly over-represented. Women aged under 35 are under-represented at both stages, while women aged 55 and over are over-represented. The proportion of women aged 35-44 in SHeS 2008 was the same as in the household population estimates. Table 1.8
Table 1.9 compares the age and sex profile of responding children at the Stage 1 interviewer visit with the mid-2008 population estimates for Scotland (the estimates for children are based on the total population, not the household population as the two measures are very similar for children and more detailed breakdowns are available for the total population). According to the 2008 population estimates boys form 51% of all children aged 0-15 and girls form 49%. In the SHeS 2008 sample, boys and girls form 50% each. The age and sex profiles of the achieved SHeS sample are very close to the population estimates for this age group. Table 1.9
1.7 WEIGHTING THE DATA
1.7.1 Overview
The SHeS 2008 comprised a general population sample (main sample), a child boost sample of children screened from additional addresses and a Health Board boost sample in three Health Board areas. As a result, several different sets of weights have been provided for the survey. This section describes the 2008 weighting procedure in more detail.
1.7.2 Adult weights - summary
Weights are provided to allow analysis of adult responders (including responders from both the main sample and the Health Board boost sample). The weighting strategy for the adult sample was:
- calculate weights (w 1) for the differential selection of addresses;
- calculate weights for the selection of dwelling units at each address (w 2) and for the selection of households at each dwelling unit (w 3);
- calibrate the combined household weight (w 1_w 2_w 3) so that the weighted sample of household members matched population estimates for age/sex and health board (w 4);
- generate weights for whether an adult within a participating household responded (w 5);
- combine w 5 with the household weight and calibrate the combined weight (w 4_w 5) to the population estimates and scale this to give the final adult interview weight, int08wt.
1.7.3 Address, dwelling unit and household selection weights
Address selection weights (w1)
Selection weights were required to ensure that each area was in the correct proportion for national estimates. The selection weights varied between Health Boards (smaller Health Boards were over-sampled so had smaller selection weights), and within each Health Board they varied by SIMD area (areas in the most deprived 15% of areas based on the 2006 SIMD were over-sampled so also had smaller selection weights).
For each stratum the selection weights were calculated as the number of addresses in the PAF divided by the number of addresses issued.
Dwelling unit and household selection weights (w2 and w3)
In a very small number of addresses the number of dwelling units found was not the equal to the MOI. In these cases a dwelling unit weight was calculated to correct for this discrepancy. A household weight was also calculated to correct for the selection of households. Without these weights households at multi-occupied addresses would be under-represented in the sample.
1.7.4 Calibrating household weights (w4)
To generate the household weights the combined selection weights (w 1_w 2_w 3) were adjusted by using calibration weighting. Calibration weighting was used to ensure that the weighted achieved sample of households matched General Register Office Scotland's ( GROS's) estimated age/sex distribution of the household population, while at the same time matching the Health Board totals.
The estimates of the household population were provided by GROS. The household population is the estimated population in private households, so excludes people living in institutions. The household population estimates used are given in Figure 1G and Figure 1H.
In addition to calibrating to the totals given in Figure 1G and Figure 1H, the weights were calibrated to ensure that the number of responding households in the deprivation areas matched the number of issued eligible households. This ensured that the SIMD15 areas were not under-represented because of non-response.
1.7.5 Adult non-response weights (w5)
It is likely that the characteristics of household members that do not take part in surveys are different from those that do. By using logistic regression it is possible to model the difference between responding and non-responding household members and, from that model, obtain weights to reduce the bias from the differential non-response.
Responding households that contained more than one adult were selected and the household weight (w 4) was applied. A logistic regression model was then fitted using variables from the household interview to model whether a household member responded or not. The final model included the following variables: the Health Board; the age/sex of the household member; the number of adults in the household; an indicator for whether the household was in an SIMD15 area; an indicator for whether the household member was in paid employment or self-employed; and a variable for the person's marital status.
The parameters in the model were used to estimate the probability of response for each individual. The adult non-response weight (w 5) was simply the reciprocal of this probability. (The adult non-response weight in households in households containing only one adult was set to 1).
1.7.6 Adult interview weights (int08wt)
The final adult interview weights were calculated by combined the household weight with the adult non-response weight (w 4_w 5) and calibrating to the totals given in Figure 1G and Figure 1H.
Calibrating to these totals ensured that when national estimates are required the age/sex and regional distributions of the adult sample match those of the population. It does not ensure that age/sex proportions are correct within each Health Board. The sample was not designed to allow yearly estimates at Health Board level, but it is likely that it will be used for this in some of the larger Health Boards, so we investigated adjusting so that the age/sex distribution was correct in these large Health Boards. This proved to be possible only in Greater Glasgow and Clyde but it will be possible to calibrate the Health Board weights to age and sex totals after four years of data collection.
Figure 1G: 2008 Mid-year household population estimates for Scotland by Health Boarda
Health Board |
Children |
Adults |
Total |
|---|---|---|---|
Ayrshire & Arran |
64,700 |
299,100 |
363,800 |
Borders |
20,100 |
91,400 |
111,500 |
Dumfries & Galloway |
25,000 |
122,000 |
147,000 |
Fife |
64,900 |
289,300 |
354,300 |
Forth Valley |
53,900 |
230,100 |
283,900 |
Grampian |
94,800 |
432,900 |
527,600 |
Greater Glasgow & Clyde |
208,200 |
966,200 |
1,174,400 |
Highland |
53,800 |
250,800 |
304,600 |
Lanarkshire |
106,300 |
450,000 |
556,300 |
Lothian |
138,500 |
661,800 |
800,300 |
Orkney |
3,400 |
16,300 |
19,700 |
Shetland |
4,200 |
17,500 |
21,700 |
Tayside |
67,700 |
321,000 |
388,700 |
Western Isles |
4,500 |
21,400 |
25,900 |
Total |
910,100 |
4,169,700 |
5,079,800 |
a Total figures may not be exact due to rounding
Figure 1H: 2008 Mid-year household population estimates for Scotland by age and sexa
Age group |
Male |
Female |
Total |
|---|---|---|---|
0-15 |
465,500 |
444,600 |
910,100 |
16-24 |
299,100 |
287,100 |
586,200 |
25-34 |
309,900 |
314,100 |
624,000 |
35-44 |
363,600 |
397,300 |
760,900 |
45-54 |
357,900 |
381,300 |
739,200 |
55-64 |
309,400 |
324,900 |
634,300 |
65-74 |
211,100 |
247,600 |
458,700 |
75+ |
140,700 |
225,600 |
366,300 |
Total |
2,457,200 |
2,622,500 |
5,079,800 |
a Total figures may not be exact due to rounding
1.7.7 Adult nurse visit weights
The sample of adults having a nurse visit was weighted to take account of differential probabilities of selection and non-response. Non-response weights were developed as the characteristics of interviewed household members that did not have a nurse visit are likely to be different from those who do. In addition, the nurse boost sample, described in Section 1.2.5 meant that the winter months would be over-represented in the sample without some form of selection weighting.
The resulting nurse weight, called nurse08wt, is a combination of selection and non-response weighting.
1.7.8 Adult blood weights
A similar method was used to generate the adult blood weights. A blood sample was not obtained from every adult who had a nurse visit so a weight was calculated to correct for non-response. The adult blood weights (blood08wt) is a combination of selection and non-response weighting.
1.7.9 Weights for the knowledge, attitudes and motivations to health ( KAM) module
KAM weights were calculated in a similar way to the main adult weights in that they combined selection weights, non-response weights and calibration.
The difference occurred in the calculation of selection weights.
- Addresses chosen for the Health Board boosts were included in the main adult weighting, but not in the KAM weighting. This meant that different address selection weights were used for adult and KAM weighting. (The dwelling unit and household weights were the same).
- Only one adult in each household was chosen for KAM. This was taken into account by deriving an additional selection weight equal to the number of adults in the household.
With these two differences a weight was calculated for analysis of the KAM sample. This is called kam08wt.
1.7.10 Child weights - summary
The weighting strategy for the child sample was:
- calculate weights (cw1) for the differential selection of addresses;
- calculate weights for the selection of dwelling units at each address (cw2) and for the selection of households at each dwelling unit (cw3);
- calculate weights (cw4) for the selection of children within each household;
- calibrate the combined child selection weight (cw1xcw2xcw3xcw4) so that the weighted sample of children matched population estimates for age/sex and Health Board. Scale this to give the final child interview weight, cint08wt.
1.7.11 The child interview weights
Address selection weights, dwelling unit and household selection weights (cw1, cw2 and cw3)
The selection weights for the addresses, dwelling units and households were generated in the same way as for the adult sample.
Weights for the selection of children at each household (cw4)
A maximum of two children were selected in each household so a selection weight (cw4) was calculated as the number of children in the household divided by the number of children selected. Without this selection weight children in larger households would have been under-represented in the final sample.
Child interview weights (cint08wt)
The final child interview weights were calculated by combined child selection weight (cw1xcw2xcw3xcw4) and calibrating to the totals given in Figure 1I and Figure 1J. A high proportion of children in participating households participated in the survey so weighting for non-response was not needed. (93% of all children selected for interview participated in the survey). Therefore, the child weight was simply the scaled calibration weight.
Calibrating to these totals ensured that when national estimates are required, the age/sex and regional distributions of the child sample match those of the population. It does not ensure that age/sex proportions are correct within each Health Board. (The sample was not designed to allow yearly estimates at Health Board level).
Figure 1I: 2008 Mid-year household population estimates for Scotland by Health Board
Health Board |
Children |
|---|---|
Ayrshire & Arran |
7.10% |
Borders |
2.20% |
Dumfries & Galloway |
2.74% |
Fife |
7.12% |
Forth Valley |
5.93% |
Grampian |
10.4% |
Greater Glasgow & Clyde |
22.84% |
Highland |
5.92% |
Lanarkshire |
11.65% |
Lothian |
15.25% |
Orkney |
0.38% |
Shetland |
0.47% |
Tayside |
7.48% |
Western Isles |
0.50% |
Total |
100.00% |
Figure 1J: 2008 Mid-year household population estimates for Scotland by age and sex (for children)
Age group |
Boys |
Girls |
Total |
|---|---|---|---|
% |
% |
% |
|
0-4 |
15.8 |
15.09 |
30.98 |
5-9 |
15.07 |
14.43 |
29.50 |
10-15 |
20.22 |
19.30 |
39.52 |
Total |
51.18 |
48.82 |
100.00 |
1.8 DATA ANALYSIS AND REPORTING
1.8.1 Introduction to response analysis
SHeS is a cross-sectional survey of the population. It examines associations between health states, personal characteristics and behaviour. However, such associations do not necessarily imply causality. In particular, associations between current health states and current behaviour need careful interpretation, as current health may reflect past, rather than present, behaviour. Similarly, current behaviour may be influenced by advice or treatment for particular health conditions.
1.8.2 Reporting age variables
Defining age for data collection
A considerable part of the data collected in the 2008 SHeS is age specific, with different questions directed to different age groups. During the interview the participant's date of birth was ascertained. For data collection purposes, a participant's age was defined as their age on their last birthday before the interview. The nurse, who visited them later, treated them as being of the same age as at the interview, even if they had an intervening birthday.
Age as an analysis variable
Age is a continuous variable, and an exact age variable on the data file expresses it as such (so that, for example, someone whose 24th birthday was on January 1 2008 and was interviewed on October 1 2008 would be classified as being aged 24.75 (24¾)).
The presentation of tabular data involves classifying the sample into year bands. This can be done in two ways, age at last birthday and 'rounded age', that is, rounded to the nearest integer. In this report all references to age are age at last birthday.
Age standardisation
Adult data have been age-standardised throughout the 2008 report to allow comparisons between groups after adjusting for the effects of any differences in their age distributions. When different sub-groups are compared in respect of a variable on which age has an important influence, any differences in age distributions between these sub-groups are likely to affect the observed differences in the proportions of interest.
It should be noted that all analyses in the report are presented separately for men and women. All age standardisation has been undertaken separately within each sex, expressing male data to the overall male population and female data to the overall female population. When comparing data for the two sexes, it should be remembered that no age standardisation has been introduced to remove the effects of the sexes' different age distributions.
Age standardisation was carried out using the direct standardisation method. The standard population to which the age distribution of sub-groups was adjusted was the mid-year 2008 census household population estimates for Scotland. The age-standardised proportion p i was calculated as follows, where p i is the age specific proportion in age group i and N i is the standard population size in age group i:
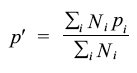
Therefore p i can be viewed as a weighted mean of p i using the weights N i. Age standardisation was carried out using the age groups: 16-24, 25-34, 35-44, 45-54, 55-64, 65-74 and 75 and over. The variance of the standardised proportion can be estimated by:
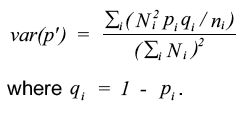
1.8.3 Standard analysis breakdowns
National Statistics Socio-Economic Classification ( NS-SEC)
The 2008 survey measured socio-economic status using the National Statistics Socio-Economic Classification ( NS-SEC) which was introduced in 2001. NS-SEC was introduced to SHeS in 2003 and replaced the social class measures used in the two previous rounds of survey, Registrar General's Social Class ( SC) and Socio-economic Group ( SEG). 9
NS-SEC was classified in two ways: on the basis of participants' own current or most recent occupation, and on the basis of the occupation details of the household reference person. The household reference person ( HRP) was defined as the householder (the person in whose name the property was owned or rented) with the highest income. If there was more than one householder and they had equal incomes, then the household reference person was the eldest. The identity of the HRP was established in the household questionnaire and details about their occupation were collected at this point. If the HRP occupational details were collected by proxy from another household member these were collected again directly from the HRP during their individual interview (if one took place). Children were assigned the NS-SEC value of the HRP.
NS-SEC is an occupational based classification that uses the Standard Occupational Classification 2000 ( SOC 2000) which replaced the Standard Occupational Classification 1990 ( SOC 90) schema. The combination of SOC 2000 and information collected about employment status (whether an employer, self-employed or employee; whether a supervisor; number of employees at the workplace) for current or last job generates the following NS-SEC analytic classes:
- Employers in large organisations, higher managerial and professional
- Lower professional and managerial; higher technical and supervisory
- Intermediate occupations
- Small employers and own account workers
- Lower supervisory and technical occupations
- Semi-routine occupations
- Routine occupations
The remaining categories include those who have never worked, or who gave no occupational details or whose information was inadequately described or unclassifiable for other reasons. Most of the analysis in the 2008 report was based on a five level version of this classification which combined the first two groups and the last two. Analysis is also possible using a three level classification which combines the intermediate and small employers and own account worker categories, and combines the lower supervisory group with the routine categories. All analysis was conduced using the NS-SEC of the HRP.
NS-SEC is a conceptually based schema which was developed from a sociological classification, the Goldthorpe Schema. 10, 11 The measure used in the 1995 and 1998 surveys, SC, used levels of occupation skill as the basis for its classification, whereas NS-SEC aims to differentiate between positions in the labour market in terms of aspects such as sources of income, job security, career advancement, authority and autonomy. A version of SC, derived from NS-SEC, has been produced by the Office for National Statistics and is available on the dataset.
Household income
The 2008 survey included questions designed to measure participants' household income. While household income alone can be used as an analysis variable, the analysis conducted for this report used an adjusted measure which took account of the number of persons within the household. The McClements method was used to equivalise incomes; this is detailed in the Glossary at the end of this report. The equivalised income measure was divided into quintiles for the presentation of analysis within the report, but the full continuous data is available on the dataset.
Scottish Index of Multiple Deprivation ( SIMD)
The analysis was based on the 2006 version of the Scottish Index of Multiple Deprivation. 12 It is based on 31 indicators in six individual domains of current income, employment, housing, health, education, skills and training and geographic access to services and telecommunications. SIMD is calculated at data zone level, enabling small pockets of deprivation to be identified. The data zones are ranked from most deprived (1) to least deprived (6505) on the overall SIMD index. The result is a comprehensive picture of relative area deprivation across Scotland. The index was divided into quintiles for the presentation of analysis within the report, a version divided into deciles is also available on the dataset. The full index is not available on the archived dataset due to concerns about its potential for identifying individual respondents or households.
1.8.4 Logistic regression
Logistic regression modelling has been used in a number of chapters to examine the factors associated with selected outcome variables, after adjusting for other predictors. For instance in Chapter 1, regression analyses have been performed to examine the association between having poor self-assessed health and a variety of predictor variables including age, income, smoking status and alcohol consumption. Forward stepwise models have been used for men and women separately. A wide range of possible predictor variables were tested in each model. This gives an estimate of the independent effect of each predictor variable on the outcome when all the other independent variables were included in the model.
The results of the regression analyses are presented in tables showing odds ratios for the final models, together with the probability that the association is statistically significant. The predictor variable is significantly associated with the outcome variable if p<0.05. The models show the odds of being in the particular category of the outcome variable (i.e. for reporting poor self-assessed health) for each category of the independent variable (e.g. quintiles of equivalised household income). Odds are expressed relative to a reference category, which has a given value of 1. Odds ratios greater than 1 indicate higher odds, and odds ratios less than 1 indicate lower odds. Also shown are the 95% confidence intervals for the odds ratios. Where the interval does not include 1, this category is significantly different from the reference category. Missing values were included in the analyses, that is, people were included even if they did not have a valid answer, score or classification in one or more of the explanatory variables. Where this was a large number of people, the missing values were included as a separate category (e.g. income), and where there were few records with a missing value, these individuals were included with the category containing the largest number of cases (e.g. non-smokers).The treatment of missing values in the regression models is explained in the footnote section of the relevant tables.
1.8.5 Design effects and true standard errors
The SHeS 2008 used a clustered, stratified multi-stage sample design. In addition, weights were applied when obtaining survey estimates. One of the effects of using the complex design and weighting is that standard errors for survey estimates are generally higher than the standard errors that would be derived from an unweighted simple random sample of the same size. The calculations of standard errors shown in tables, and comments on statistical significance throughout the report, have taken the clustering, stratification and weighting into account. The ratio of the standard error of the complex sample to that of a simple random sample of the same size is known as the design factor. Put another way, the design factor (or 'deft') is the factor by which the standard error of an estimate from a simple random sample has to be multiplied to give the true standard error of the complex design. The true standard errors and defts for the SHeS 2008 have been calculated using a Taylor Series expansion method. The deft values and true standard errors (which are themselves estimates subject to random sampling error) are shown in Tables 1.11 to 1.18 for selected survey estimates presented in the main report. Tables 1.11 to 1.18