Citizens' Jury on QCovid: Report on the jury's conclusions and key findings
Ipsos Scotland was commissioned to conduct a Citizens' Jury exploring views on QCovid®. QCovid® is a risk model developed to identify people at the highest risk of death or a poor outcome should they catch Covid-19. This report documents the Citizens' Jury process and findings.
6. Population-level tool: using non-anonymised data
Introduction
Using non-anonymised data at the population level would involve running a risk prediction model like QCovid® through health records at a national level to identify those individuals who would be at the highest risk of dying or becoming seriously ill from Covid-19. Anyone identified in this way would then be informed that they were highest risk and could be added to the highest risk list.
Information about this tool was provided to participants in stages. In sessions three and four, participants heard presentations from expert speakers on how QCovid® was used at the population level in England (by Professor Aziz Sheikh) and specifically its use by the JCVI to identify people who should be prioritised for vaccines (by Professor Jeremy Brown). They then heard presentations explaining the potential risks and benefits of using data at the population level (by Dr Helen Stagg), and the current processes in place for collecting and protecting health data (by Professor Alison McCallum). Participants reflected on the presentations and had the opportunity to ask questions.
In sessions five and six, participants deliberated on the tool, including its application for different individuals (who varied in terms their age, health, risk level and attitudes towards data privacy), and under different scenarios related to the pandemic (e.g. a new variant, waning vaccine effectiveness, low prevalence) before drawing conclusions.
Summary and principles
Views on the use of this tool developed over the course of the jury and it was clear that the process of learning and deliberation had an impact on participants' attitudes. In the early stages of the process, participants were somewhat apprehensive about this tool, raising several questions and concerns about its application in terms of data accuracy, security and potential stigmatisation. In later sessions, they moved to a position of general support for this tool, having had some of their initial concerns addressed. It is important to note, however, that support for this tool was predicated on certain conditions being met.
The jury concluded that the use of such a tool in Scotland, as part of the QCovid® model or a similar risk model, would only be acceptable if:
- Information about the tool, including the reasons for using it and what a person should do if they are notified as being at high risk, is available and clearly communicated to the public (without jargon).
- There is sufficient targeted support in place to help people notified understand their risk score and infrastructure in place for people (e.g. for essential items or services).
- There is clear information about the sources of support available and that support is easy to access.
- The score is stored confidentially to the individual with no legal requirement to share, to minimise risk of stigma or discrimination.
- The tool is kept up to date in case of people moving from low risk to high risk (and vice versa) based on new evidence or changing circumstances (including in relation to the virus e.g. new variant), and people are duly notified of changes to their risk level.
- There is a mechanism to challenge or change the outcome.
- There are data security protocols in place to ensure the tool is used only by the Scottish Government and NHS Scotland. In the case of QCovid®, this would be for the purpose of identifying and supporting people at risk of Covid-19 or other serious viruses.
The jury concluded that the use this tool would be unacceptable if:
- Data about individuals is shared with third parties for purposes that do not align with healthcare-related public benefits relating to the pandemic.
- There is not adequate ongoing support in place to help people who are identified as being at high risk.
- The data is not held securely.
- The risk to public health from Covid-19, or another virus, at the time is minimal.
- It is used to discriminate against individuals (e.g in the workplace or in accessing services such as insurance).
Risks and benefits
There was broad agreement on the risks associated with the use of non-anonymnous data at the population level. Some of these echo the risks already noted in relation to the clinical and public facing tools. The perceived risks were:
- If the underlying data is not accurate (i.e. if it does reflect changes in the circumstances associated with the pandemic) then it could incorrectly identify some people as being at high risk. This could lead to negative impacts on people's wellbeing.
- Potential lack of support for people notified as being at high risk, which could, again, lead to emotional distress and negative impacts on their wellbeing.
- Issues around stigma could arise (for example, being treated differently in other areas of healthcare or in employment as a result of the risk score).
- Data security, with the risk of possible breaches or data getting into the wrong hands. Linked to this was a perceived risk of scope creep, with questions raised about whether the data might be used for purposes beyond the risk prediction.
- Consent would be difficult (if not impossible) to obtain, leaving people with limited control over how their data is used.
The key perceived benefits of this tool were that:
- It would enable individuals to be informed about their risk. Participants generally felt that the ultimate aim of the tool – to identify those at risk and help them to take the right course of action with the right support – was a good thing (though questions were raised about how individuals would be informed, as discussed below).
- It would allow a targeted response to the management of the pandemic, which keeps people at higher risk safe while avoiding large-scale interventions (such as national or regional lockdowns).
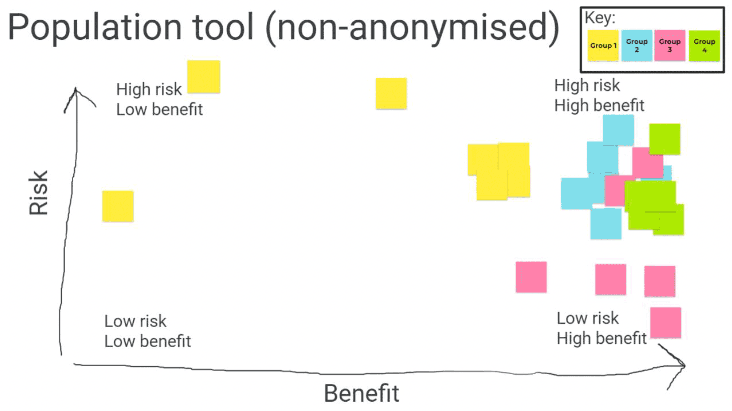
Overall, as illustrated in figure 5 overleaf, the population tool using non-anonymised data was seen as relatively of benefit. In particular, the ability to target individuals most at risk and help them to respond accordingly was seen as one of the most important benefits of this tool, making it stand out from the others. Views on the risks of the tool were more mixed, but overall it was seen as relatively high risk. The most pressing risks were those related to support for high risk individuals, and risks of data security - as one participant put it "by the very nature of making the data non-anonymised, this is going to be a higher risk than the other population tool".
Key ethical considerations
The key ethical concerns that remained for participants at the end of the process centred around the following themes.
Accuracy
The need for accuracy of the population level tool, both in terms of the data underlying it and the outcome it produced, was underpinned by a concern about the impact on individuals identified as being at high risk. Participants highlighted the negative impacts of a high risk classification on an individual's mental health and wellbeing, and reference was made to how difficult the shielding experience had been on individuals (including some of the participants themselves) early in the pandemic. Because of these potential risks, the accuracy of the risk prediction was considered essential.
"I think when they're using big data, it's good for making broad decisions about how to deploy vaccines and resources because you don't need a very accurate model to do that. When you're asking people to sit at home and not see anyone for 6, 12, 18 months, that requires a higher level of accuracy."
(Participant in session 1)
On the other hand, there was also a view that non-anonymised data allowed for a more targeted, and therefore more accurate, response to managing the pandemic than if anonymised data was used. Indeed, this was ultimately seen as one of the benefits of this tool.
"My brother has a rare condition and wasn't told to be on a shielding list and is healthy in all other aspects apart from that one condition. Only non-anonymised data can pick up on those conditions that people can have. Anonymised data may not be as accurate or personalised when it comes to healthcare delivery."
(Participant in session 4)
Support
The need for support for individuals identified at risk was one of the strongest themes to emerge in the discussions around the non-anonymised population tool. As noted above, participants were aware of the potentially negative impacts on individuals' mental health and wellbeing if they were told they were at risk. It was therefore seen as essential that support was provided to those individuals and this support would need to have multiple elements:
- Emotional – to offer reassurance to people receiving a score which is upsetting to them.
- Interpretative - to help people understand their risk score and what it means.
- Practical – to help people understand what steps they needed to take to protect themselves and others, and support to help make sure they could access what they needed (e.g. access to food and essential items if they were being asked to shield).
Data security
The security and privacy of data was another core consideration for this tool, because the data would contain information that could identify individuals. Following the presentation on the existing data protocols that NHS Scotland have in place (including the process used by the Public Benefits and Privacy Panel), participants felt more reassured about the security of public health data than they had been at the beginning of the process. Nonetheless, potential data breaches or data getting into the wrong hands remained risks they associated with this tool.
The overall importance of data privacy led the jury to establish the principle that data security protocols should be place to ensure that the data is only used to identify and support people at risk of Covid-19 or other viruses. Protecting the data against unwarranted access from third parties was also a key consideration for the jury – and one of the unacceptable aspects of the tool was the sharing of non-anonymised data with third parties that might use it for purposes not aligned with public health benefits related to the pandemic.
Consent
Related to data security and privacy is the issue of consent. It was acknowledged that gaining consent from everyone whose data might be used at the population level would be very difficult if not impossible. Lack of consent, however, was not an issue that would make this tool unacceptable to the jury; they felt that the overall benefits of the tool warranted the use of data without individuals' consent, as long as the principles around data security were in place.
Confidentiality
One of the perceived risks of this tool was the potential stigma that an individual with a high risk score might experience. For example, that score might impact on what type of medical treatment they get access to in future or might impact beyond the healthcare setting and into decisions around employment, insurance, or other services. To help counter this risk, participants felt it was important that an individual's risk score remained confidential and was not shared outside of the healthcare setting (for example with employers or insurance companies). Added to this, participants felt that there should be no legal requirement for the individual to share that information themselves.
Communication
Participants felt it was important that the public was made aware of the use of the population tool using non-anonymised data. They felt this would help make the process more transparent and help make clear to the public how their data was being managed and used. There was general agreement that the scale of the data (with potentially millions of health records being used) made it difficult to inform every individual that their non-anonymised data had been used. However, two levels of communication were suggested for this tool.
Firstly, providing information in a centralised place – such as the NHS Scotland website or the Scottish Government website (with alternatives for those not online) – explaining what the risk prediction model was, along with why and how people's data were being used. Secondly, communication with the individuals identified as being at high risk. This latter form of communication was seen as a key part of the process of providing support for those at high risk, and the overall sentiment was that individuals should not only be informed about their risk score but provided with advice and signposting to resources that could help them take appropriate action.
Circumstances for using the non-anonymised population-level tool
In session four, participants considered a range of scenarios in which the population-level tool might be deployed using non-anonymised data, and discussed the extent to which its use would be acceptable or not.
The scenarios included:
- If a new variant emerges which appeared to be resistant to the vaccine.
- If the effectiveness of the vaccine was waning against the existing variants.
- If there was a low prevalence of Covid-19 in society.
Generally, participants felt the public health benefits of the non-anonymised population level tool justified its use, as long as certain conditions (the jury's principles) were met. This sentiment did not change much under the scenarios, with the exception of low prevalence (see below). Across each scenario, participants stressed the importance of having a clear rationale for using non-anonymised data and for that rationale to be communicated in some way to the public.
New variant
If a new variant emerged, it was felt that use of the population tool with non- anonymised data might become more important than it is now, as the need to identify those most at risk would be heightened. The nature or severity of a new variant was not defined in this hypothetical scenario. However, participants felt that use of the tool would become even more acceptable if that new variant was more transmissible, or had more serious health impacts, than current variants. It was felt that the potential severity of the variant and its impacts on people's health could make the benefits of using the tool outweigh the risks – even more so than in the current situation.
"It's even more important to use the non-anonymised version in this scenario… The intensity for using it is greater in this circumstance and the actions that people are advised to take might need to be modified if it's a very resistant and damaging variant."
(Participants in session 4)
The perceived benefits of using the tool under this scenario were that it would help individuals get prioritised for vaccines or vaccine boosters, and that it would generally help the health service prepare its response to the variant. Reflecting on this scenario, participants also emphasised the importance of people "doing their bit" to help manage virus, and that we should therefore be prepared to accept non- anonymised data being used in these circumstances.
"I think, we should be doing everything within our power to help the frontline… we have to take a bit of a reality check and do everything we can. So, if [the Covid-19] comes back, everybody is prepared. Especially those who are vulnerable, to ensure they get the care they should."
(Participant in session 4)
However, there was still caution expressed about use of this tool if a new variant emerged. Participants emphasised the need to maintain the principles of transparency and the importance of data not being shared with third parties unrelated to managing public health during the pandemic. They also felt that a new variant might emphasise the need for the tool to be updated to reflect any differences in the level of risks to particular groups from the variant.
In one group, there was a preference for using the anonymised population-level tool in the first instance, with the non-anonymised population-level tool being introduced only if a new variant would significantly impact particular groups and that there was a clear rationale for identifying and notifying those affected.
"The default should always be anonymised data. If there was another strain and you were rolling out another vaccine, I don't think you need to know specifically who needs it, you could use a group of people. If the variant is worse for people in a certain age range with a certain disease, non-anonymised data use might make sense. When it comes down to using the tool, it should be anonymised data first."
(Participant in session 4)
Waning vaccine effectiveness
If vaccine effectiveness was waning, views on the use of this tool did not change much compared to other situations discussed, such as the current situation (at the time of research) or a new variant. Participants were still broadly supportive of the use of the population level tool with non-anonymised data, if the conditions previously discussed were in place. One group put forward the view that this scenario was actually fairly close to the current position, as vaccine effectiveness can ultimately wane over time.
In either of the above scenarios, the same principles applied related to accuracy, support, data security, confidentiality and communication. In considering the possibility of a new variant or waning vaccines, participants also emphasised the importance of the tool being able to adapt to changing circumstances.
Low prevalence
If there was low prevalence, then the benefits of using this were less clear – it was felt that with less need to manage the spread of the virus and lower risk of transmission, then the risks associated with this tool (data security, stigma, potential lack of support) might outweigh the benefits.
"If the risks to society are on a whole low, I'd start to question what's the reason to do it at all. It goes back to what the benefit is of telling people they are high risk, if there is a low risk in general of catching it. I would start to move against [support for this tool] in that case."
(Participant in session 4).
This scenario also led to questioning of the value for money of the investment in this tool, and the view that it would potentially be a waste of resources. For some, this meant that use of the tool would no longer be acceptable.
"If it was low [prevalence] I would have to ask why they are using non-anonymised data. I would say there is a need for a public tool rather than a population tool. Why waste money and a huge number of resources for non-anonymised data? That would be a red line for me."
(Participant in session 5).
Contact
Email: shielding@gov.scot