Using intersectionality to understand structural inequality in Scotland: evidence synthesis
An evidence synthesis of literature on the concept of intersectionality. Looks at what the concept means, and how it can be applied to policymaking and analysis, as well as providing spotlight examples.
6. How can intersectionality be integrated throughout the analytical process?
Intersectionality has traditionally been applied in qualitative research to understand the lived experience of people in groups experiencing disadvantage. However, intersectionality can be used in both qualitative and quantitative research.[83] Recent years have seen a growing number of academic papers highlighting the importance of intersectional quantitative analysis across a number of disciplines.[84],[85] This section of the report outlines how intersectionality can be integrated throughout the analytical process, with a particular focus on addressing power imbalance in research; ensuring marginalised groups are reached, and data analysis approaches.
Adopting an intersectional approach within an analytical context involves a number of considerations in relation to the participant or respondent sample, the wider context that may influence inequality and the ways in which the diverse experiences of the group of interest will be captured. Analysts looking to utilise the techniques discussed should access further information in the cited references and listed in Section 8.
The Global Partnership for Sustainable Development Data recently produced resources on intersectional approaches to data.[86] They set out that "Intersectional approaches to data identify inequality within and between groups of people based on the way multiple facets of an individual's identify interact. They ensure that data contributes to the reduction of inequality - which includes using intersectionality as a lens through which to examine data practices, processes, and institutions reflectively".[87] With this in mind, they provide five recommendations for implementing an intersectional approach to data, which are summarised in the box below.
The Global Partnership for Sustainable Development Data recommendations for governments and organisations implementing an intersectional approach to data:
- Establish a commitment to centering the voices of individuals at the greatest risk of marginalisation or discrimination in all aspects of data systems and practice. This means accepting that lived experience is a valid form of evidence of inequality or discrimination, and ensuring that those individuals who are most impacted by inequality or discrimination are included in processes to identify solutions, develop organisational projects and programmes, or create policy.
- Promote equity across the entire data value chain. For intersectional approaches, data must promote equity for people who face the greatest risk across data collection, publication, uptake and impact.
- Ensure that institutional data systems are inclusive and safe. Intersectional approaches work to make data systems more inclusive, including taking into account different kinds of data.
- Engage data to increase context awareness and reduce inequality. Intersectional approaches to data should be adopted by governments and organisations to improve the quality of life of people who have been affected by intersecting inequality.
- Build inclusive data institutions. High priority should be placed on diversity and inclusion in the workforce, and analysts should critically assess how elements of their own identity shapes the data they collect, analyse and use.
6.1 Embedding an intersectional approach to data
The Global Partnership for Sustainable Development Data[88] provides a number of
tips for analysts looking to embed an intersectional approach to data in existing practice or design new intersectional data initiatives. They recommend establishing intersectional approaches to data in progressive stages as organisational expertise is established through:
- Clarifying intent. Agreeing aims and objectives for the intersectional approach to data, including priority areas of policy or practice.
- Engaging stakeholders. Collaborating with marginalised groups directly or organisations representing them.
- Advocating for time and budget. Perform a data gap analysis to determine what data is available and what data is needed.
- Establishing roles and responsibilities. Engage in capacity building across the organisation to increase knowledge and awareness of intersectional approaches to data.
- Developing action plans. Produce action plans to solidify commitment and operate as an accountability mechanism.
6.2 Posing critical questions
A number of resources suggest that analysts should pose a number of critical questions throughout the research process.[89],[90] For example, Cole suggested that analysts seek to answer three questions throughout at each stage of the research process: [91]
1. Who is included within this group or category?
2. What role does inequality play, including the privilege and power experienced by this group?
3. What are the similarities across groups that are often viewed as different?
The implications of Cole's three questions for each stage of the research process are presented in Table 4 below.
Table 4: Cole's critical questions and their implications for each stage of the research process[92]
Research Stage: Generation of hypotheses
Who is included within this category?
Attuned to diversity within categories.
What role does inequality play?
Literature review attends to social and historical contexts of inequality.
Where are the similarities?
May be exploratory rather than hypothesis testing to discover similarities.
Research Stage: Sampling
Who is included within this category?
Focuses on neglected groups.
What role does inequality play?
Category memberships mark groups with unequal access to power and resources.
Where are the similarities?
Includes diverse groups connected by common relationships to social and institutional power.
Research Stage: Operationalisation
Who is included within this category?
Develops measures from the perspective of the group being studied.
What role does inequality play?
If comparative, differences are conceptualised as stemming from structural inequality rather than as primarily individual-level differences
Where are the similarities?
Views social categories in terms of individual and institutional practices rather than primarily as characteristics of individuals.
Research Stage: Analysis
Who is included within this category?
Attends to diversity within a group and may be conducted separately for each group studied.
What role does inequality play?
Tests for both similarities and differences.
Where are the similarities?
Interest not limited to differences.
Research Stage: Interpretation of findings
Who is included within this category?
No group's findings are interpreted to represent a universal or normative experience.
What role does inequality play?
Differences are interpreted in light of groups' structural positions.
Where are the similarities?
Sensitivity to nuanced variations across groups is maintained even when similarities are identified.
Likewise, the Global Partnership for Sustainable Development Data[93] argue that equity is promoted across the entire data value chain by posing critical questions such as:
- Data collection: Who has been included in identifying what data to collect and how to collect it?
- Data publication: Who is doing the analysis and what do they know about intersecting inequalities?
- Data uptake: How can data be combined and used to tell a story of intersecting inequality and influence policy?
- Data impact: How has inequality been reduced and how do we measure this?
The remainder of this section provides an overview of the available literature to suggest how an intersectional approach could practicably be applied through the research process to understand structural inequality, and monitor and evaluate policy.
6.3. Addressing the power imbalance in research
6.3.1 Reflexivity
Reflexivity is an important part of conducting intersectional research; a researcher should ask themselves questions about their own social positions, values, assumptions, interests and experiences and how these can shape the research process, as well as putting the research into context.[94] Regarding these principles, Grabe has highlighted that any intersectional research, whether it be qualitative, quantitative or mixed methods, requires this sort of critical self-reflexivity which has historically been more common in qualitative research.[95]
Abrams and colleagues argue that practices such as reflexive journaling (i.e., written systematic self-awareness) and bracketing (i.e., identification and suspension of researcher biases) have been useful in helping researchers understand the influence of their personal identities and associated biases on the research process, including study conceptualising, participant recruitment, data collection, and data analysis.[96] Reflexive journaling involves a researcher keeping a written record of their research process where they reflect on what they did, thought and felt throughout the research process. The purpose of bracketing is to mitigate the negative effects of unacknowledged preconceptions related to a research project. In undertaking the process of bracketing the researcher should suspend their beliefs, assumptions, biases and previous experience in order to see and describe a phenomenon. This works hand-in-hand with reflexive journaling, where a researcher is able to fully reflect on what their preconceived belief, assumptions and biases are.
For researchers who do share backgrounds or experiences with participants, employing "caring reflexivity" by opening dialogue with participants about power imbalances and concerns during the study can enhance trust and build rapport.[97] Where this is not possible the researcher should familiarise themselves with some of the issues described by people with that identity, and to acknowledge to participants that they do not share their identity.[98]
6.3.2. Public involvement in research
While nearly all research involves participants and participation of some sort, public involvement in research is distinct because the contributions of researchers and community member participants are viewed as equally valuable, with each seen as having unique expertise throughout the research process.[99]
Public involvement refers to the active involvement of people with lived experience in research projects and in research organisations.[100] This is distinct from more traditional research approaches in which people take part in a research study as 'participants' or 'data subjects' (e.g. being interviews or answering questions about their experiences) and where information gathered through research is disseminated to people rather than with them. The National Institute for Health Research define public involvement as "research being carried out 'with' or 'by' members of the public rather than 'to', 'about' or 'for' them.[101]
Public involvement can be a strong way to ensure that marginalised communities, such as those with intersecting protected characteristics, are actively engaged in research from conceptualisation through implementation and dissemination.[102] Involving people with lived experience could take a number of forms, including through[103]:
- Consultation
- Advisory or steering groups
- Public advisors
- Peer researchers
- Priority setting partnerships
- Co-production
- User-led research
Table 5 sets out ways in which people with lived experience of intersecting protected characteristics could be involved throughout the research process.
Table 5: Ways that people with lived experience could be involved in different stages of a research project.[104]
Research stage
Identifying and prioritising
Public involvement
- Setting research priorities and aims.
- Consulting with organisations who represent those with lived experience to develop research questions.
- Holding a consultation event or workshop.
- Carrying out a scoping study.
Research stage
Commissioning
Public involvement
- Involving people with lived experience in drafting specifications and evaluating tenders.
- Asking organisations representing those with lived experience to commission the research.
- Build in public involvement approaches as a requirement of the tender.
- Involve people with lived experience in the ongoing contract management of the research, including through project advisory groups or direct contract management.
Research stage
Research design and management
Public involvement
Consult or collaborate with people with lived experience and/or organisations representing people with lived experience to:
- Develop research questions and proposals.
- Develop recruitment materials and data collection tools.
- Check feasibility of research methods.
- Identify additional public involvement opportunities.
Research stage
Carrying out the research
Public involvement
- Representation on project steering groups.
- Contribute to literature reviews.
- Collect data through peer research, including by co-facilitating focus groups or interviews with peers and other stakeholders.
- Contribute to data analysis, including by identifying priorities for analysis, identifying themes in qualitative data.
Research stage
Reporting and dissemination
Public involvement
- Contribute to report drafting.
- Producing other outputs to disseminate findings, including accessible summaries, blog posts, videos, social media posts.
- Sharing findings with their networks.
- Co-presenting findings at events.
- Contribute to the development of dissemination plans.
It is important to note, however, that when public involvement is attempted without equity between researcher and those with lived experience there is a risk that it could be seen as tokenistic and could perpetuate any pre-existing power imbalances. Talat Yaqoob[105], campaigner and researcher with a speciality in intersectional approaches, identified six foundations that are key to public involvement in research:
1. Trust in the public
2. Financial resources
3. Adequate time allocated
4. Clarity and accessibility
5. Redistribution of power
6. The right techniques should be used for the right project
INVOLVE set out a series out a series of values and principles for effective public involvement[106]:
- Respect. Researchers, research organisations and the public respect each other's roles.
- Support. All have access to practical and organisational support to involve and be involved.
- Transparency. All are clear and open about the aims and scope of involvement.
- Responsiveness. Researchers and research organisations actively respond to the input of public members involved in research.
- Fairness of opportunity. Relevant groups should be given equal opportunity and efforts are made to ensure involvement is inclusive and seldom heard voices are represented.
- Accountability. All are accountable for their involvement in research and to the people, communities and groups affected by the research.
6.3.3. Examples of public involvement in research
This section provides some examples of public involvement in research to illustrate the principles outlined above. Note, however, that whilst public involvement in research is key to engaging with the concept of intersectionality, the examples provided below did not necessarily explicitly set out to explore disadvantage through an intersectional lens.
Talat Yaqoob identified examples of effective participatory community research. One such example is provided in the box below.
Social action during the coronavirus pandemic
This research, undertaken by The Collective Consultancy[107], aimed to better understand the role of "social action"; how people come together to improve their lives and the implications of this for creating a fairer Scotland. The COVID-19 pandemic was identified as an opportunity to learn about informal social action in response to a crisis.
In order to explore social action community research was employed, which focuses on research being fully lead by grassroots community members. 18 community researchers were recruited (based on the type of social action they delivered and their geography, to ensure wide representation across Scotland), and trained in order to build skills on how to develop survey questions, how to conduct research, survey ethics and distribution. Community researchers were paid £200 for their time and input.
Community research usually involves the method of the research, the research questions, the delivery, the analysis and write-up being fully conducted by community members. This project, however, already had pre-defined research questions, so a pre-made survey of nine questions was created with three additional questions for each community researcher to develop themselves, which were relevant to their own communities and which investigated issues they felt were pertinent to their local area.
Key findings included:
- The most common social action efforts were food distribution/collection, grocery or prescription pick-ups for neighbours and befriending or "checking-in" with isolating/ shielding neighbours.
- 44% of participants were also getting social action support (e.g. through a foodbank).
- 51% of participants felt there was an increase in community frustration at ongoing inequality.
- 64% felt there was a reduction in stigma in coming forward for support.
- Participants emphasised the need to not view social action through "rose-tinted glasses" but to understand that many social action interventions are a direct result of poverty, exclusion and inequality.
- Respondents explained that they felt empowered by supporting their communities but equally disempowered by the impact of inequality and feeling that their communities were being overlooked.
Co-production was carried out by the Scottish Government to develop the social security system in Scotland through Social Security Scotland's Experience Panels:
Social Security Scotland – Co-designing the Social Security Charter and Measurement Framework
The Social Security (Scotland) Act 2018 makes provision for the production of a Charter and Measurement Framework, to be made in consultation with people with lived experience of the social security system.[108] A group of diverse people with a range of conditions and experiences (the Core Group) – made up mostly of 'Experience Panel' members – have taken part in workshops with Scottish Government analysts to create the charter, based on the principles in The Act.
The co-design of the Charter Measurement Framework was undertaken between March and August 2019. Scottish Government officials held:
- Seven full-day workshops with Core Group 2, including an advice and discussion session between the group and the Scottish Commission on Social Security (SCoSS)
- Two meetings with representatives from stakeholder groups
- Two meetings with SCoSS
Crucial elements of the co-design process included:
- Enabling participation: breaking down barriers to participation through, for example, using sign language interpreters and audio describers where necessary. All written materials used by the group were made available in accessible formats, for example, large print or different colour contrast, where needed.
- Power: group decision making and ownership about the process of producing the Charter Measurement Framework and the processes' outputs.
- Knowledge: capacity building with participants; guests, including policy colleagues and minister, to inform group of latest developments/answer questions; knowledge exchange – recognising lived experience as expertise.
6.4 Ensuring marginalised groups are reached
Adopting an intersectional approach to analysis requires that people with different intersecting identities, particularly from multiple marginalised groups, be included in research so that their voices are heard.[109]
Practical steps that can be taken to aid diverse research recruitment, including:
- Considering the timing of the research recruitment. For example, where intersections of religion or belief are relevant, this could involve avoiding significant religious and cultural days when scheduling research.
- Using fully accessible venues that are appealing and well located for your target groups.
- Asking participants in advance if they have any particular dietary or access requirements that you may be able to accommodate; considering diverse dietary requirements and preferences when providing refreshments (for example provision of vegetarian and non-vegetarian food, specifying that any meat served be halal).
- Considering the provision of incentives and expenses to value research participants' time and contribution.[110]
- Equality monitoring to ensure an appropriate range of participants, as well as to document who the research participants were. Monitoring may be done at different stages: during research recruitment, to ensure a diverse range of the target group is registering to participate, or to target underrepresented groups if not; and at the point of the research being conducted.[111]
- Ensuring that you are not overburdening the same groups or individuals. Where there are multiple research projects intending to reach groups with the same intersecting identities, try to join up to minimise burden.
6.4.1. Sampling techniques
The sampling techniques used in research are important considerations when taking an intersectional approach. A completely random sampling approach or use of a sampling frame designed to be representative of a whole population may lead to problems with low sample size for lower-frequency groups in the population or among those who may be more reluctant to take part in research.
Insufficient sample size is a particular barrier to taking an intersectional approach so analysts should consider all available techniques and the implications. Analysis of data with small subsamples of certain groups has the potential to commit the "lumping error" in which samples of heterogeneous groups are treated as homogeneous because they are too small to be divided into appropriate subgroups (e.g. minority ethnic vs. White). It is noted, however, that there is sometimes no alternative where sample sizes are low so, in instances where this is considered inadequate to meet the requirement, alternative more targeted sampling techniques should be considered.[112]
Where random sampling will not provide a sufficiently large sample size to produce robust insights into the experiences of those with intersecting characteristics, sampling might take one of two forms:
- Stratified random sampling for a between-group design[113]
- Purposive, quota or snowball sampling for between- or within-groups designs.
Stratified random sampling requires researchers to decide on the intersectional groups that will be considered in the research and then sample those groups to ensure equal numbers of individuals are included. Stratified random sampling is a method of sampling from a population whereby the population is divided into subgroups and individuals are randomly selected from the subgroups.[114] Low-frequency groups may be best dealt with using stratified random sampling (e.g. minority ethnic groups).
Purposive, quota or snowball sampling may be the most useful for those applying an intersectional approach to qualitative research.[115] This can be used to develop a sample that is representative or typical of the intersectional group of interest, through recruitment of participants through networks or by asking research participants to refer eligible peers.[116] Purposive and quota sampling are similar as both strategies facilitate the identification of participants based on preselected criteria relevant to the research question. Purposive, quota or snowball sampling may be most effective is implemented as part of a wider public involvement approach to the research, as outlined earlier in this Section.
Respondent-driven sampling or snowball sampling, involves asking or incentivising participants to recruit additional participants. This can be particularly useful for targeting those with stigmatised or hidden identities.[117] For example, the National LGBT Survey published by the UK Government Equalities Office in 2018, was an online survey which utilised respondent-driven sampling in order to access a large number of respondents. This was considered important given the lack of data on the LGBT population in national and administrative datasets. The survey achieved a sample of 108,100 responses by wide promotion by the Government Equalities Office, stakeholders, at national LGBT pride events, via national media coverage and on social media.[118]
Respondent-driven sampling can also be strengthened by vocal support from a community leader, as they may provide guidance on effective recruitment techniques, help researchers establish trust with potential participants, and assist researchers in pre-emptively addressing concerns community members may have about the research project.[119] However, respondent-driven sampling is biased toward inclusion of individuals with interrelations, which can potentially limit diversity of the sample and contribute to a greater likelihood of missing individuals who are not connected to the accessed social network.[120]
Researchers may consider combining sampling approaches to minimise selection bias and related threats to the trustworthiness of data. Combining strategies (e.g., employing quota and snowball sampling online and in community-based settings) may better capture participants who are considered "hard to reach," especially if the identities of the population of interest are hidden or associated with illegal activity (e.g., illicit drug use or sex work).[121]
6.5 Approaches to intersectional research design
There is no 'one' intersectional research approach. For example, looking across academic disciplines at the applications of intersectionality within quantitative research, McCall[122] and Walby[123] distinguish between three main forms of intersectionality:
- Anticategorical complexity: deconstruction of analytical categories such as gender and race, and focuses attention on the ways in which concepts, terms and categories are constructed. Most commonly applied in historical and literary studies.
- Intracategorical complexity: focuses on particular groups at neglected points of intersection. Case studies, ethnographic and narrative research methods are the primary focus.
- Intercategorical complexity: makes strategic use of categories and analyses relations of multiple inequalities between groups. This approach orientates itself towards the relationship between categories mainly in quantitative research. For example, modelling income-differences between fixed social groups. In this method, categories of interest are selected in advance.
Most research using quantitative methods or data analysis techniques has been intercategorical, generally describing inequalities across intersections, whereas qualitative research tends to be intracategorical.
In practice, when planning research, analysts often have to decide between within-groups designs, between-groups designs or some combination of the two. This is likewise reflected in the available intersectional research literature. Some studies use a within-group design (e.g. studying one intersectional group, such as disabled women) whereas other studies use a between groups design to sample and compare multiple groups, e.g. 2 (gender: women vs. men) by 2 (disability: disabled/non-disabled) design.[124] As a means to understand the experiences of those with intersecting characteristics, each of these designs have relative merits and disadvantages, which are described in the box below.
A within-groups design can provide a rich understanding about a specific intersectional group, offer new insights and lead to new research questions. However, a within-groups design is less informative to our understanding of how intersectional groups compare because of the exclusion of other intersections. This design assumes, but cannot test, how having multiple intersecting characteristics shapes experiences. Having a single group sample could increase the risk of overgeneralisation of research findings.[125]
A between-groups design involves at least four comparing groups, such as disabled women vs. disabled men vs. non-disabled women vs. non-disabled men. More complex between-groups designs may involve comparing three or more characteristics, such as 2 (gender: women vs. men) x 2 (age: younger vs. older) x 2 (disability: disabled vs. non-disabled). However, depending on the research question(s) it may be appropriate to combine the within- and between-groups designs, such that variations in one category (e.g. disabled vs. non-disabled) are examined within one group (e.g. women).
6.6. Approaches to intersectional data analysis
There are few standard practices for intersectional statistical analysis, although several different approaches have been proposed.[126] A selection of these approaches are presented below. It is accepted that it may not be possible to apply all of these statistical techniques within the context of public sector analysis as result of limited sample sizes, resource and time constraints. However, it is important to explore a range of options in order to incorporate their principles where possible and relevant.
It is important to note that combining the use of lived experience research with important statistical analysis in the form of population surveys can be particularly helpful in determining how frequent the experiences of those with intersecting characteristics are, and also useful for identifying key areas for further research. Small sample sizes can hinder this analysis, but it is important that an analyst thinks creatively when faced with this issue. A solution, which is often employed by Scottish Government population surveys, can be to combine multiple years' worth of data in order to increase sample size, although it is important to note that is easier to achieve in some cases than others. For example, it is easier to achieve a good sample size when looking at sex by age (e.g. the experiences of young women) compared to looking at age by sexual orientation.
6.6.1. Cross-tabulation analysis
Most work on study design or data analysis methods has been intercategorical, generally describing inequalities across intersections.[127] This is the approach most commonly adopted within public sector analysis in Scotland; quantitative applications of intersectionality within official or national statistics, and Scottish Government research publications, have tended to focus on presenting measures of central tendency of outcomes across two or more protected characteristics. Cross-tabulations are particularly useful if an analyst wants to explore the experiences of those with intersecting characteristics using existing data. For example, the Annual Population Survey, which provides statistics on Scotland's labour market, explores how the minority ethnic employment gap varies by gender, and by age. The minority ethnic employment gap is the gap in employment rates between the minority ethnic[128] and white populations. The research found that the minority ethnic employment gap was estimated at 13.2 percentage points for women and at 2.2 percentage points for men. In addition, in April 2020-March 2021, the minority ethnic employment gap was estimated to be largest for those aged 25 to 34 (16.7 percentage points); followed by ages 35 to 49 (14.4 percentage points), ages 16 to 24 (7.2* percentage points) and ages 50 to 64 (-8.3 percentage points, where the minority ethnic employment rate is higher than the white employment rate).[129]
Cross tabulation tables are useful when analysing the relationship between two or more categorical variables, such as protected characteristics. For example, weekly statistics are released by Public Health Scotland on COVID-19 provides vaccine uptake statistics by age and ethnicity, ethnicity and health board, and SIMD decile, age and health board.[130] However, whilst cross tabulation tables are helpful in presenting descriptive statistics, inferential statistics are required to examine the relationships between variables within a sample and make generalisations about how these variables relate to the larger population. In addition, the documentation of inequality, even in finer intersectional detail, has been criticised by academics as it can serve to reinforce ideas of inherent differences between groups rather than to point towards actionable solutions.[131],[132]
6.6.2. Interactions within multiple regression models
According to Scott and Siltanen[133] it is potentially helpful to move beyond the descriptive approach outlined above to inferential techniques that test whether differences between groups are statistically significant.
One approach to analysing intersectionality is to use multiple regression.[134] Multiple regression allows analysts to model the relationship between several variables, such that several variables predict a change in an outcome.[135] Crucially, multiple regression allows analysts to investigate how variables interact to predict a change in an outcome. This allows analysts to take intersectionality into account in their inferential statistical analysis.
For example, an additive regression model, such as "Outcome = Disability + Gender + Sexual Orientation" is not an intersectional model. It can be used to understand the effects of one of the predictors (e.g. Disability) whilst holding the other variables constant (e.g. Gender and Sexual Orientation). However, this does not allow for intersectional analysis because it does not show the impact of individual characteristics when the others are allowed to vary.
To carry out intersectional analysis, it is key to include an interaction term within a multiple regression model. For example, "Outcome = Disability * Gender * Sexual Orientation". With an interaction term, it is possible to answer the question of how the outcome changes for different combinations of variables.
An example of the use of interactions within multiple regression to identify intersectional inequality is available within the Sightsavers case study prepared by the Inclusive Data Charter.[136]
Sightsavers is an international organization that collaborates with partners in developing countries to eradicate preventable blindness and promote equal opportunity for disabled people. In 2019, Sightsavers sought to identify the social inequalities that influence access to treatment for cataracts in Kogi, Nigeria. After cleaning and preparing the data, Sightsavers tested for univariate associations, that is specific associations between two variables only, identifying factors to examine based on their background knowledge.
However, in order to produce an intersectional analysis the Sightsavers team adopted a multivariable method in which they developed a regression model by combining factors that they believed would have a relationship with the outcomes: age, sex, wealth, and disability. Since they approached the outcomes as binary, they chose to use a logistic regression model, which provided an output including odds ratios describing the strength of effect of each factor and a p-value representing the likelihood that the observed relationship occurred by chance.
The team went one step further in their exploration of intersectional effects and decided to test a pre-specified hypothesis that a particular sub-group of participants had a specific level of risk linked to a specific combination of their identity factors. In this situation, they added an interaction term to their model which allowed them to explore whether the specific effects of disability were moderated by gender or age.
The Sightsavers case study highlights a number of key considerations for analysts undertaking an analysis of interactions within multiple regression models:
- When using multiple regression models analysts should question where data comes from and whether individual characteristics were measured appropriately in the first place.
- Analysts should question their results and whether multivariable models reflect the logical mechanism and pre-existing evidence behind observed relationships when analysing and interpreting data.[137]
There are a number of advantages and disadvantages to this approach, which are represented in Table 5 below.
Table 5: Advantages and disadvantages of interactions within multiple regression models
Advantages
This is standard multiple regression so represents a commonly used technique to test for statistical significance.[138]
Interaction terms are useful because they help identify multiplicative effects that may characterise inequalities beyond additive effects.[139]
Three-way interactions bring a more nuanced perspective of intersectionality, especially when a contextual variable (such as characteristics of a local labour market) is included as a component of the interaction.[140]
Disadvantages
Interaction effects are not estimated in isolation from the main effects of the variables from which they derive, but rather the significance of interaction is contingent on the size of the main effects (e.g. race and gender). In addition, categories such as race and gender might exert effects that contradict or cancel each other out, reflecting buffering or moderation of disadvantage by advantage.[141]
Interpreting interaction terms can be challenging when both main and interaction effects are included in the model, especially with higher-order interactions of three or more predictors.[142]
There may be difficulties understanding the impact of contextual variables when they are conceived as independent variables in the regression model – context is treated not as its own level of analysis but as an individual-level characteristic when presented in the higher-order interaction terms.[143]
Critics[144] argue that the inclusion of statistical interactions is not sufficient for an approach to be considered intersectional; researchers must also consider the meaning and underlying processes of the interactions.
Moderate amounts of data, skills, and resources required to undertake this type of analysis.[145]
6.6.3. Comparing multiple regressions run within different contextual variables
Scott and Siltanen[146] argue that in order to achieve a deeper appreciation of contextual variations of complex inequalities "we must move beyond the analysis of main effects, control variables and interaction effects afforded by a single multiple regression model." They suggest running separate regression models within different contextual variables to compare relevant axes of inequality within and across contexts.[147] As set out in Section 3 above, an understanding that the inequality conferred by intersecting identities varies according to context, is key to the concept of intersectionality.
Contextual variables could, for example, be the school, city, workplace or neighbourhood which influences the relative advantages and disadvantages experienced by those with intersecting characteristics. Within data analysis, it is possible to begin to take into examine the effects of context by running multiple separate regression models within different contexts (e.g. schools) and comparing the predictive effect of the interacting characteristics (e.g. race and sex) on the outcome variable (e.g. educational attainment scores).
However, an inspection of the outputs of each of these models, would not provide a way to statistically test whether there are any statistically significant differences between the intersecting effects of gender and race between these contexts (in our example, schools).
To test for a significant difference due to context, researchers require an integrated dataset so that separate regression equations can be estimated for the categories of contextually-relevant variables and the average difference in outcome variables across the different contexts can be partitioned into two parts.
Table 6, below, demonstrates the main advantages and disadvantages of this method.
Table 6: Advantages and disadvantages of comparing multiple regressions run within different contextual variables.
Advantages
Separate models allow regression coefficients for additive and multiplicative effects to vary, which helps the researcher explore and determine, rather than assume a priori, what focal and contributing factors are operating in tandem to produce a unique configuration of inequality.[148]
Disadvantages
Like statistical interactions within multiple regression, this approach has the limitation that it is fundamentally based on data measured exclusively at the individual level of analysis. These models [149], therefore, do not incorporate into the analysis variation that corresponds directly with the characteristics of contexts themselves.[150]
6.6.4. Multilevel Models
Conventional regression models ignore that people are 'nested' within contexts that influence the extent to which various characteristics confer advantage or disadvantage, such as neighbourhoods, schools, workplaces or localised labour markets.[151] Multilevel models recognise that outcomes are likely to be a combination of an individual's characteristics and the social context in which they are embedded. Multilevel models have the feature of incorporating contextual information differently for each individual within a single model.
A multilevel model uses a system of equations that identifies values of an outcome variable as a function of explanatory variables for individual characteristics (level 1) and explanatory variables for context level characteristics (level 2).[152] For example, a multilevel model would allow analysts to examine differences in educational attainment scores according to the intersecting protected characteristics of race and sex accounting for differences between teachers and schools.
Scott and Siltanen argue that multilevel models offer an analytical approach that most closely matches the features of intersectional analysis highlighted in the literature, including attention to context, identifying relevant dimensions of inequality and accounting for the complex, multidimensional structure of inequality. Table 7 below demonstrates some of the main advantages and disadvantages of multilevel models.
Table 7: Advantages and disadvantages of multilevel models
Advantages
Allows researchers to explore how contextual characteristics reconfigure individual level relationships through the inclusion of a cross-level interaction.[153]
Disadvantages
Multilevel models have stringent dataset requirements: the researcher needs to be able to situate every respondent within theoretically significant contexts and in turn have access to information on all relevant contextual variables included in the analysis.[154]
There are likely to be challenges relating to weighting estimates and having a sufficient sample size.[155]
Critics[156] of using interaction effects to achieve intersectional models argue that such an approach does not capture the nuance of intersectionality. Social categories, such as race and gender, are confounded in individuals; this means that any survey question that asks participants to report whether their experiences were a function of one category membership rather than another may be eliciting flawed data.[157]
6.6.5. Moderated Mediation
Else-Quest and Hyde present moderated mediation as another statistical technique that could be used for intersectional analysis.[158] Moderated mediation tests whether the effect of the influence of a mediating variable (M) on the relationship between an independent variable (X) and an outcome variable (Y) is moderated (i.e. modified) by a fourth variable (Z).
Else-Quest and Hyde reference intersectional research carried out by Harackiewicz and colleagues[159] that investigated the intersection between race and social class using a moderated mediation model to test the effectiveness of an intervention among students taking a biology course. As depicted in Figure 3, the mediation model examined whether the effectiveness of the intervention on attainment (course grade) was mediated by student's engagement in the course (as measured by the length of their essays). Crucially, the model examined whether the effectiveness of the intervention on students' engagement was moderated by the effects of the students' race and whether the students were the first generation in their family to attend college. The use of moderated mediation in this research revealed that first generation minority ethnic students showed the greatest gains resulting from the intervention on engagement and course grades.
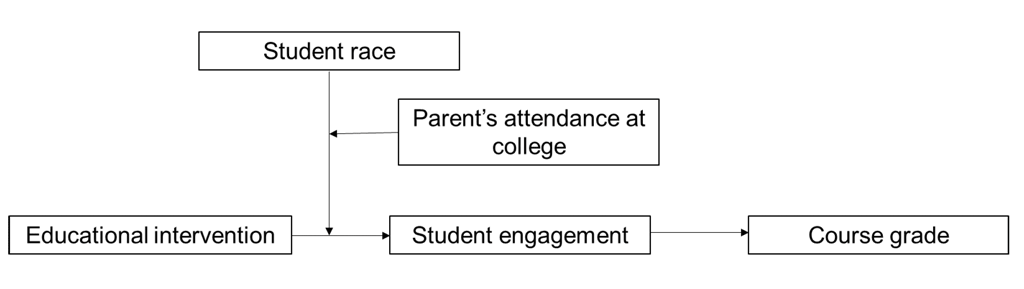
Table 8 below demonstrates some of the main advantages and disadvantages of moderated mediation.
Table 8: Advantages and disadvantages of moderated mediation
Advantages
Allows analysts to examine whether the effectiveness of an intervention on an outcome is moderated by intersecting identities. This has the potential to be useful when monitoring and evaluating policies.[160]
Disadvantages
Where mediation models include a moderator variable, it is essential that there is a large enough sample size in each subgroup of the moderator variable. As with other inferential techniques, analysts should ensure that they have sufficient 'statistical power' to detect the effects of interest.[161]
Data about the moderating equality characteristics is required from each person participating in the intervention.[162]
Moderated mediation favours longitudinal research designs in which data on an outcome variable is obtained following the implementation of an intervention.[163]