Scottish household survey 2018: methodology and fieldwork outcomes
Methodology of the Scottish household survey 2018 and information on fieldwork targets and outcomes.
5 Data Processing
Summary
- Data checks are important to maintain the high quality of the data. The main data file was subject to checks and editing involving range checks, simple logic checks and complex logic checks.
- The data then underwent two additional processes. Firstly, the calculation of derived variables such as the age and sex of the Highest Income Householder and secondly, the imputation of household income.
- Within the SHS, total net annual household income remains the main indicator of household income. A proportion of respondents either did not know how much they received or refused to say how much they received. In order to rectify this non-response, and produce an accurate measure of total net household income, missing values were imputed.
- The edited data was delivered to the Scottish Government, who ran further checks on the data.
- Physical survey data was also subject to a rigorous validation process to ensure the accuracy and validity of each item of data entered. This included range checks on all fields.
5.1 Social data processing
The social data processing routines are summarised in Figure 5.1.
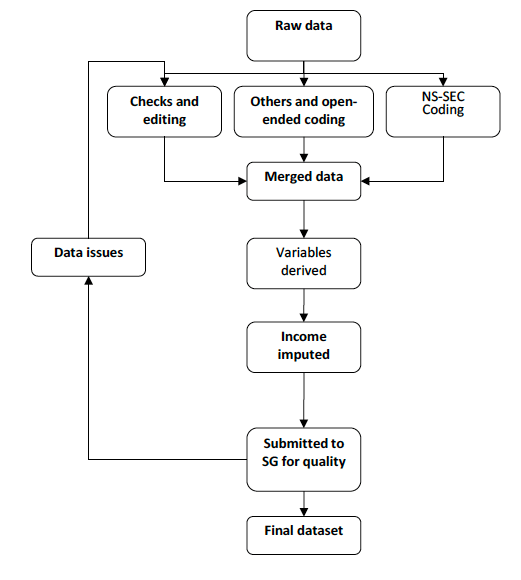
The raw data was initially split into 3 files. Data from the 'other (write in)' variables and open-ended data was extracted for coding separately. Additionally, the variables used to produce NS-SEC variables were extracted into a separate file for coding.[15]
The main data file was subject to checks and editing involving:
- Range checks, confirming that all variables were within the acceptable limits established for the question concerned.
- Simple logic checks ensuring the relationships between questions were logical. For example, that the number of people answering a filtered question is equal to the number of people giving the appropriate response at the filtering question e.g. if 500 people say they smoke then the number of people giving a response to the number of cigarettes they smoke needs to be 500.
- Complex logic checks. These involved examining the relationships between variables and assessing the logic of combinations of responses. Combinations of age and working status, age and relationships to other household members, for example, were checked to assess the logic of someone aged over 60 years and coded as the child of another household member.
The data then underwent two additional processes. Firstly, the calculation of derived variables such as the age and sex of the Highest Income Householder, and secondly, the imputation of household income. The edited data was delivered to the Scottish Government, who ran further checks on the data. Any data issues identified by Scottish Government were discussed and, where necessary, corrected and the data processing routines were amended.
Standard validation checks raised doubts on the accuracy of a small number of interviews. For these interviews, verification of the original interview was sought. Where the householder confirmed that no interview had been conducted, they were invited to participate. Where no-contact was subsequently made with the original household, the initial suspect interview was discarded, and a systematically selected household was chosen to replace this address. This replacement selection was undertaken to ensure the sample remained representative in terms of SIMD, Rural-Urban classification and datazone. Any addresses where a replacement has been used, the original address has been removed from any results and any calculations presented on SHS 2018 data, including this report.
5.1.1 Imputation of income in social data
Within the SHS, total net annual household income remains the main indicator of household income. Prior to 2018 this was defined as the total income from earnings, benefits and a variety of miscellaneous sources for the Highest Income Householder and their spouse, where applicable, with each component of income collected separately. In 2018 the definition was widened to include up to three other adults in the household, where applicable. In the 2018 survey 17 per cent of households had other adults (i.e. adults other than the Highest Income Householder and their spouse) and it was found that more than half (54 per cent) of these adults had earnings.
A proportion of respondents either did not know how much they received or refused to say how much they received. In order to rectify this non-response, and produce an accurate measure of total net household income, missing values were imputed.
The process used for the Highest Income Household and their spouse was similar to that which has been used in previous years. A modified version of this process was used for the imputation of the missing income of the other adults in the household.
Missing income data was imputed for each component of income separately:
- earnings from main jobs and other jobs[16];
- 40 different benefit components[17]; and
- ten different components of miscellaneous income.
Before starting the imputation process, the raw data was fully cleaned. For income from benefits, the upper limit of entitlement for each benefit was calculated. Any cases which were above these thresholds were examined, and edited if necessary. It is possible that respondents over-estimate income from one source of benefit and under-estimate income from another. Therefore, in cases where the benefit level was marginally above the threshold, the amount was not edited, but the case was excluded from use as a donor case in the imputation process.
Unlike benefits, clear rules do not exist regarding upper and lower limits of earnings and sources of miscellaneous income. These were examined against key indicators - such as tenure, NS-SEC, and description of employment - and were either edited or excluded from the imputation process.
Imputation of earnings has the largest effect on total net household income because of the proportion of cases with missing earnings data and the fact that earnings are commonly the main source of household income. For earnings from main and other jobs, imputed values were calculated using Hot Deck imputation. In Hot Deck imputation respondents are sorted into imputation groups according to likely determinants. Cases with missing data are donated values from cases with data which are in their imputation groups, according to the characteristics chosen. The determinants were selected from a regression model that related earnings to a set of explanatory variables, such as age and sex, full-time or part-time employment, car ownership, tenure, receipt of means tested benefits, and NS-SEC. When selecting the determinants for Other Adults variables such as the relationship to the Highest Income Householder were also used.
Imputation of income from benefits was undertaken for each benefit separately. For benefits which were received by only a few people, no modelling could be undertaken and the median value of receipt for these benefits was imputed. For other benefits which are received by a significant number of respondents (e.g. State Retirement Pension), Hot Deck imputation was used, with the imputation classes reflecting the entitlement rules as closely as possible. Imputation of income from benefits was undertaken after imputation of earnings and other sources of income, as income from benefits can be dependent on the income of the household.
Imputation of miscellaneous income was undertaken separately. Most miscellaneous sources of income were received by a small number of respondents and no modelling could be undertaken. The median value of receipt was imputed for these components. For components where modelling could be undertaken (e.g. Investment income, non-State pensions and Student loans) - Hot Deck imputation was used, with the imputation classes based on the variables in the models that had the most explanatory power.
Following imputation, income from all components were summed to create a total net household income variable. All households with a net total household income were set to 'missing' if the computed figure was less than £25 a week. Although a small proportion of households will have had a lower income than this – and be living off savings or loans – it is likely that some households will have either under-reported receipt of benefits or earnings, or the imputation process has resulted in a low value being given.
Overall, imputation was undertaken for one or more component in 43.8 per cent of households. After imputation, household income was missing for 4.2 per cent of households.
With imputation, there is a danger that the donor groups may differ from those with missing information. While this factor can be minimised with careful specification, it can never be totally excluded. In order to guard against analyses that might be sensitive to the imputation procedures, a set of flag variables were created in order that analysts could identify cases and components where income had been imputed.
5.2 Physical survey data validation
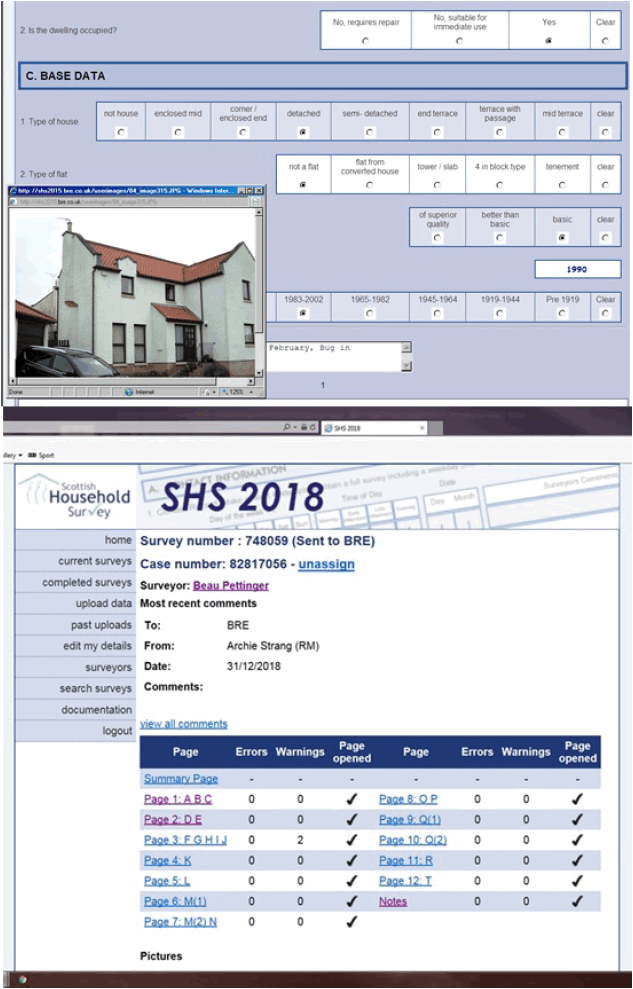
The data from the physical survey forms were uploaded into the physical survey validation system together with the photographs of each dwelling.
The validation system worked by applying a set of rules (the same rules as used in previous years) provided by the Scottish Government, to the raw data, to ensure the accuracy and validity of each item of data entered. This included range checks on all fields, detailed consistency checks making use of the redundancy built into the survey schedule and plausibility checks on all appropriate items. Rules cross-reference different parts of the survey form (e.g. if the dwelling is a house, then aspects of common dwelling section should not be completed; if the house is a flat, then details for common parts should be present).
Surveyors were shown a list of all the errors picked up by the validation program. Additionally, they were shown a list of all the entered data, with a description of the variable next to each bit of data, and with the data split into representations of each page of the form. The validation system showed the data and the failed edits as well as showing the photographs of the property.
Corrections were then made and each form rechecked until it passed all edits. Changes to the data were made simply by overtyping the incorrect data where it was displayed. Once a surveyor had completed validation, the data was forwarded to their Regional Manager for sign-off. Validation of each form was completed when all errors had been eliminated or a supervisor had determined that the dwelling genuinely falls outside the validation criteria. An audit trail of changes made to the data was kept.
Contact
Email: shs@gov.scot