Scottish Health Survey - topic report: The Glasgow Effect
Topic report in the Scottish Health Survey series investigating the existence of
Appendix 1: Pseudo R 2s
A variety of approaches exist for developing a pseudo R 2, based on the different approaches for thinking about R 2s in ordinary least squares regression, which enable comparisons to be made between models 16. The two most appropriate approaches are considering R 2 as the proportion of the total variability that is explained by the model, and the improvement in prediction from the null model to the fitted model.
McFadden's pseudo R 2 mirrors both of these approaches, and is calculated as follows:
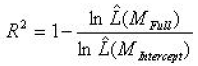
where ![]() is the estimated likelihood, M Full is the model with predictors and M Intercept is the model without predictors. The higher the R 2, the better the fit of the full model compared to the intercept model. If two models were being compared on the same data, McFadden's pseudo R 2 is higher for the model with the higher likelihood, indicating the model which fits the data better. This therefore enables models to be directly compared to find which of the discussed models best fits the data.
is the estimated likelihood, M Full is the model with predictors and M Intercept is the model without predictors. The higher the R 2, the better the fit of the full model compared to the intercept model. If two models were being compared on the same data, McFadden's pseudo R 2 is higher for the model with the higher likelihood, indicating the model which fits the data better. This therefore enables models to be directly compared to find which of the discussed models best fits the data.